TurboQuant가 시장을 흔든 진짜 이유: AI 최적화는 이제 메인스트림

Jaehoon Lee
Technical Content Manager, Nota AI
지난 3월, Google 연구진의 공식 발표 하나에 미국 증시의 인프라·반도체 관련주 시가총액 수조 원이 요동쳤습니다. 바로 대형 언어 모델(LLM)의 핵심 병목인 KV 캐시를 단 3.5비트 수준으로 압축해 메모리 사용량을 6분의 1로 줄였다는 'TurboQuant' 연구 결과입니다. "AI 모델이 메모리를 이토록 적게 쓴다면, 향후 HBM 수요가 급감하는 것 아니냐"는 공포가 시장을 덮친 것입니다.
그러나 조금 더 깊이 들어가 보면 이야기가 달라집니다. 현재 기업용 AI나 멀티 에이전트(Multi-agent) 환경에서 요구하는 긴 문맥(Long-context) 처리 비용은 여전히 대중화하기엔 너무 비쌉니다. 즉, 압축을 통해 비용이 6분의 1로 줄어든다는 것은 수요의 감소가 아니라, 그동안 비싼 비용 탓에 억눌려 있던 거대한 엔터프라이즈 수요를 폭발시키는 '언락(Unlock)'의 신호탄으로 해석할 수 있습니다.
이처럼 다양한 해석과 엇갈린 전망이 오가고 있지만, 우리가 주목해야 할 것은 아직 실환경 검증도 끝나지 않은 연구 단계의 알고리즘 하나에 시장이 이토록 민감하게 반응했다는 사실 자체입니다. 이 현상을 단순한 기술적 해프닝으로 넘기기엔 시장의 움직임은 너무나도 즉각적이고 거대했습니다.
왜 이 알고리즘 하나에 수조 원이 움직였는지, 그 배경에 있는 세 가지 결정적 시그널을 조명해 보겠습니다.
1. 거시적 시그널: 1000배의 진단과 'Joule당 지능'의 부상
먼저, 이 움직임의 배경부터 봐야 합니다. AI 산업 전체가 효율의 벽에 부딪히고 있습니다.
올해 3월, AI 4대 석학 얀 르쿤(Yann LeCun) 교수를 비롯해 Google, NVIDIA, OpenAI, Stanford, AMD, SK Hynix 등 30개 이상 기관의 연구자들이 공동으로 발표한 "AI+HW 2035: Shaping the Next Decade"가 그 진단의 결과물입니다. 경쟁 관계인 이들이 뜻을 모은 이유는 하나, AI와 하드웨어의 다음 10년을 위해 지금 방향을 잡지 않으면 안 된다는 절박함이었습니다.
보고서의 핵심 메시지는 명확합니다.
"향후 10년간 AI 학습·추론 효율을 1000배 개선해야 한다."
그동안 AI 업계의 유일한 진리는 '거거익선(Bigger is Better)'이었습니다. 더 큰 모델, 더 많은 파라미터, 더 긴 컨텍스트. 하지만 보고서가 제시하는 숫자는 냉정합니다. 단일 프런티어 모델 하나를 학습하는 데 수백만 킬로와트시의 에너지가 소모되며, AI 데이터센터의 전력 수요는 국가 단위에 근접하는 수준으로 치솟고 있습니다. 이 궤적대로라면, 이번 10년이 끝나기 전에 프런티어 모델 하나의 학습 비용이 소규모 국가의 연간 전력 소비량과 맞먹게 됩니다.
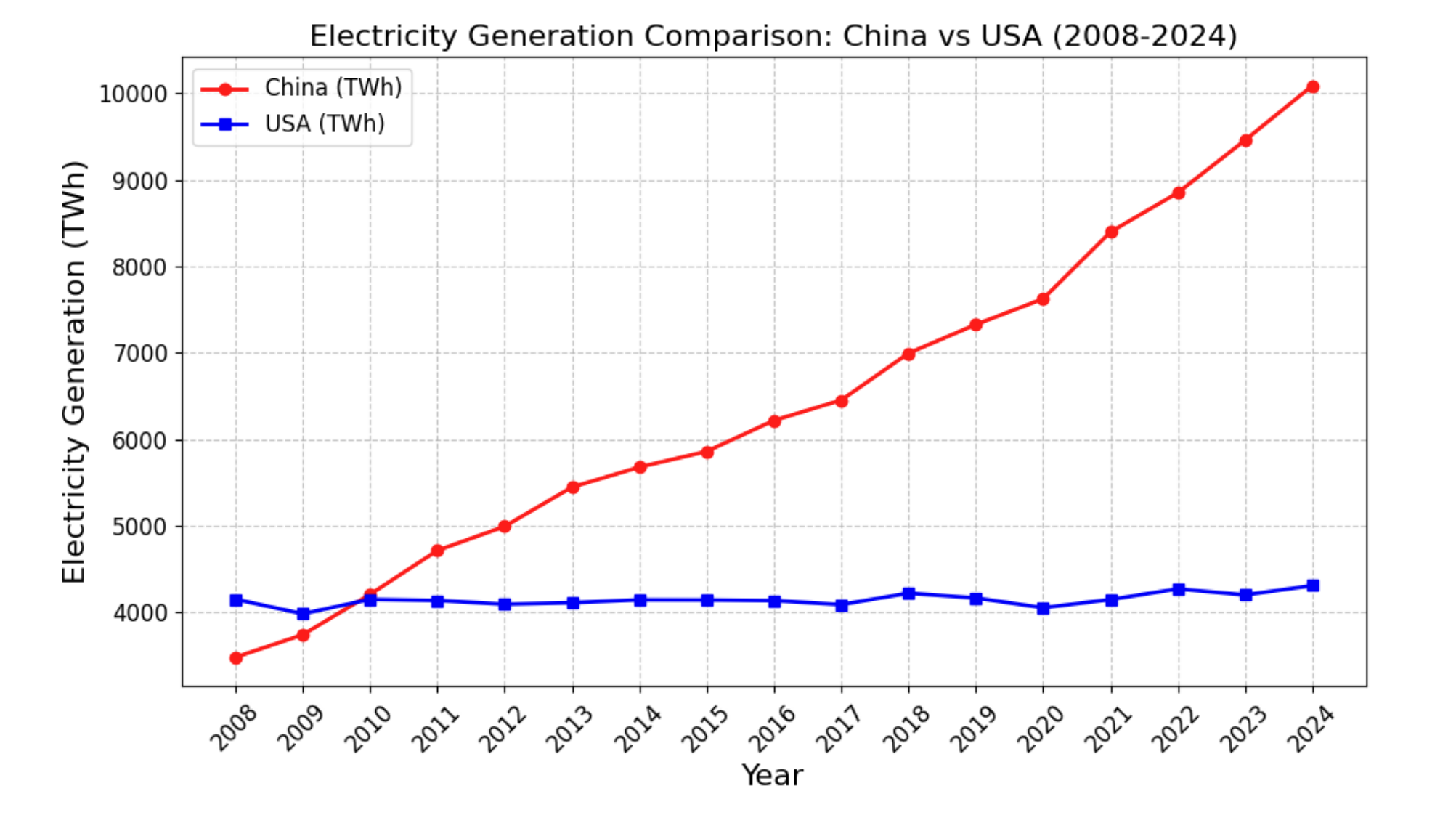
사진1: 중국과 미국의 전력 생산량 비교(2008–2024). 중국은 약 3배 증가한 반면 미국은 정체 상태로, AI 시대 에너지 효율 개선의 필요성을 시사한다. (출처 : AI+HW 2035)
보고서가 지목하는 근본 원인은 메모리 월(Memory Wall)입니다. 오늘날 AI 시스템에서 데이터를 이동하는 데 드는 에너지는 연산 자체에 드는 에너지를 이미 넘어섰습니다. 칩의 연산 속도를 아무리 올려도, 데이터를 가져오는 병목이 풀리지 않으면 전체 시스템 효율은 제자리입니다. 이 문제를 풀려면 하드웨어만 바꿔서는 안 됩니다. 알고리즘이 애초에 움직여야 할 데이터의 양 자체를 줄여야 합니다.
그래서 이 보고서는 다가올 10년의 최우선 과제로 전례 없는 수준의 효율 개선을 정의합니다. 보고서에 따르면, 이 목표는 단일 레이어의 점진적 개선으로는 도달할 수 없으며, 하드웨어·알고리즘·시스템 아키텍처 전 계층의 혁신이 곱으로 작용해야 비로소 가능합니다. 성공의 척도 자체도 바뀝니다. 더 이상 단순한 연산량(FLOPs)이 아니라, 1줄(Joule)의 에너지로 얼마나 의미 있는 결과를 만들어내는지를 뜻하는 '에너지당 지능(Intelligence per Joule)'이 새로운 기준선이 됩니다.
보고서의 알고리즘 레이어에서 가장 먼저 명시하는 핵심 방향 역시 이와 정확히 맞닿아 있습니다. 바로 양자화(quantization), 가지치기(pruning), 그리고 고급 모델 압축(Advanced Model Compression)입니다.
2. 하드웨어의 시그널: NVIDIA의 '토큰 공장 경제학'
이 거시적 진단은 이미 하드웨어에서 실행되고 있습니다.
지난달 막을 내린 NVIDIA GTC 2026에서, 젠슨 황(Jensen Huang) CEO는 데이터센터를 '토큰을 생산하는 공장(Token Factory)'에 비유하며 새로운 경제 공식을 제시했습니다.
Revenue = Tokens per Watt × Available Gigawatts
이 공식이 의미하는 바는 명확합니다. AI 공장의 전력 한도는 고정되어 있습니다. 1 기가와트 공장은 2 기가와트 공장이 될 수 없습니다. 그렇다면 수익을 결정짓는 변수는 단 하나, 바로 '와트당 토큰 생산량'입니다. 즉, 같은 전력으로 얼마나 많은 추론을 해낼 수 있는지가 관건입니다. 단순히 GPU를 사 모으는 것으로는 더 이상 비즈니스 타산이 맞지 않으며, 인프라의 크기를 키우는 단계를 지나 철저한 최적화와 전문화로 국면이 전환되었음을 룰 메이커 스스로 증명한 것입니다.
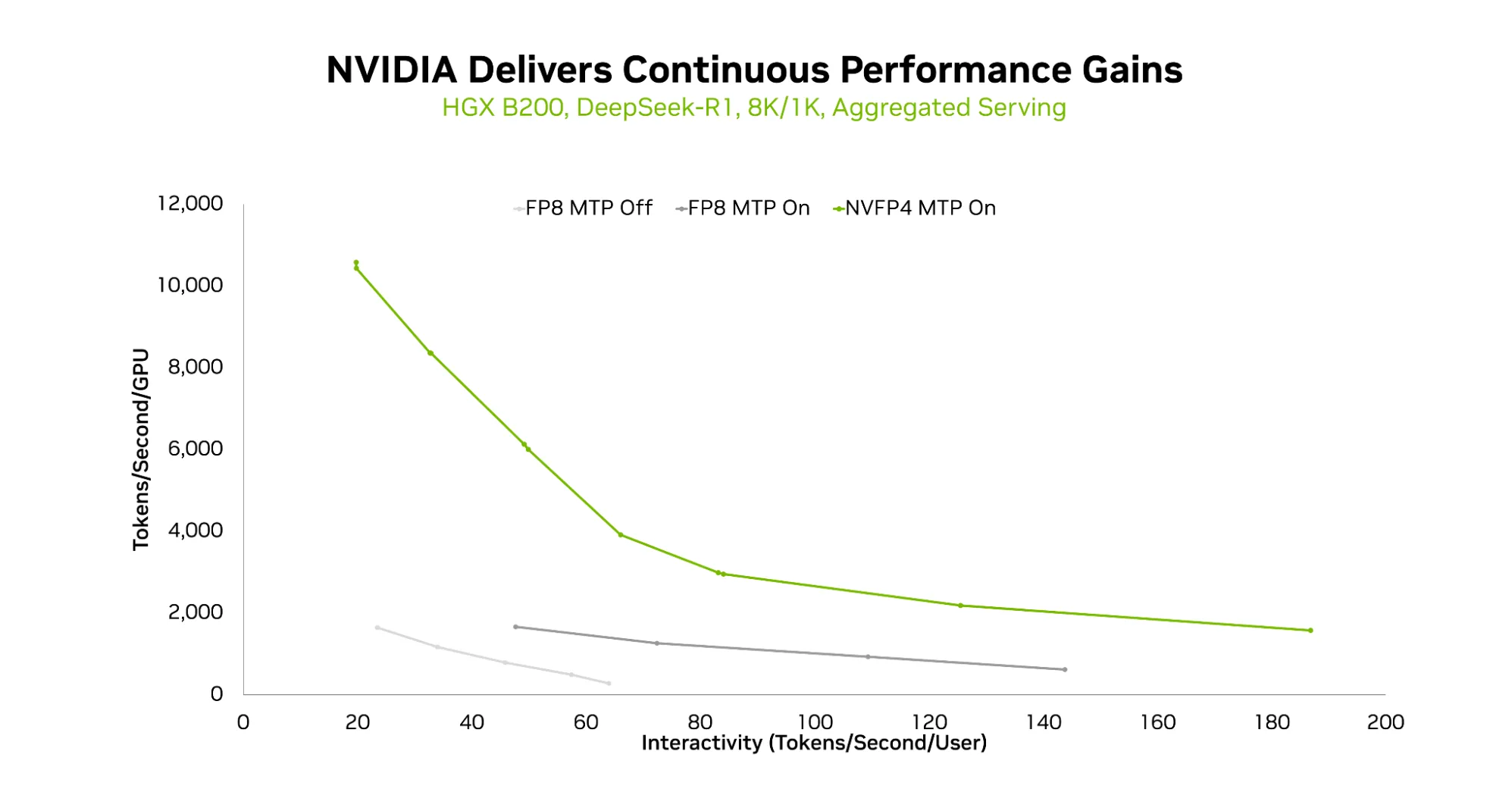
사진2: NVIDIA HGX B200에서 DeepSeek-R1 서빙 시 정밀도별 처리량 비교. NVFP4(4비트)+MTP 설정이 FP8 대비 약 2배의 처리량을 달성한다. (출처 : NVIDIA Technical Blog)
NVIDIA는 말만 한 것이 아닙니다. Blackwell 아키텍처의 5세대 텐서코어에는 NVFP4, 즉 4비트 부동소수점 연산이 네이티브로 내장되어 있습니다. FP8 대비 연산 처리량 약 2배, 메모리 사용량 1.8배 절감. DeepSeek-R1 같은 대형 모델을 FP4로 양자화해도 정확도 손실 1% 이내. TensorRT-LLM, vLLM 등 주요 서빙 프레임워크에도 이미 네이티브 지원이 들어가 있습니다.
NVIDIA는 여기서 멈추지 않았습니다. 지난해 말 추론 전용 칩 스타트업 Groq를 200억 달러에 인수하고, 그 기술을 차세대 Vera Rubin 플랫폼에 통합하겠다고 발표했습니다. Blackwell에서 Vera Rubin까지의 구매 주문 전망치는 2027년까지 1조 달러.
보통은 알고리즘이 발전하면 하드웨어가 수동적으로 그 연산량을 감당한다고 생각합니다. 하지만 지금은 하드웨어가 먼저 4비트 네이티브 연산을 전면에 내세우며, '이제 이 규격에 맞춰 최적화하라'라고 시장의 판을 깔아주고 있습니다. 룰 메이커가 이 정도로 확실하게 베팅했다면, 저비트 양자화는 더 이상 실험실의 트릭이 아닙니다.
3. 알고리즘의 시그널: TurboQuant, 그 기술의 실체
산업의 방향이 정해지고 하드웨어가 준비된 바로 그 자리에, 정확히 같은 방향을 향해 날아온 것이 바로 TurboQuant입니다. 이제 인트로에서 언급했던, 시장을 흔든 이 기술의 실체를 들여다볼 차례입니다.
Google Research가 공개한 TurboQuant는 KV 캐시를 단 3.5비트 수준으로 압축하여, 메모리 사용량을 약 6배나 줄이면서도 16비트 원본의 압도적인 성능은 그대로 유지합니다.특히, 캘리브레이션 데이터셋이나 파인튜닝 등 추가적인 학습 과정 없이(Data-oblivious) 즉시 적용 가능하다는 점이 가장 큰 강점입니다.
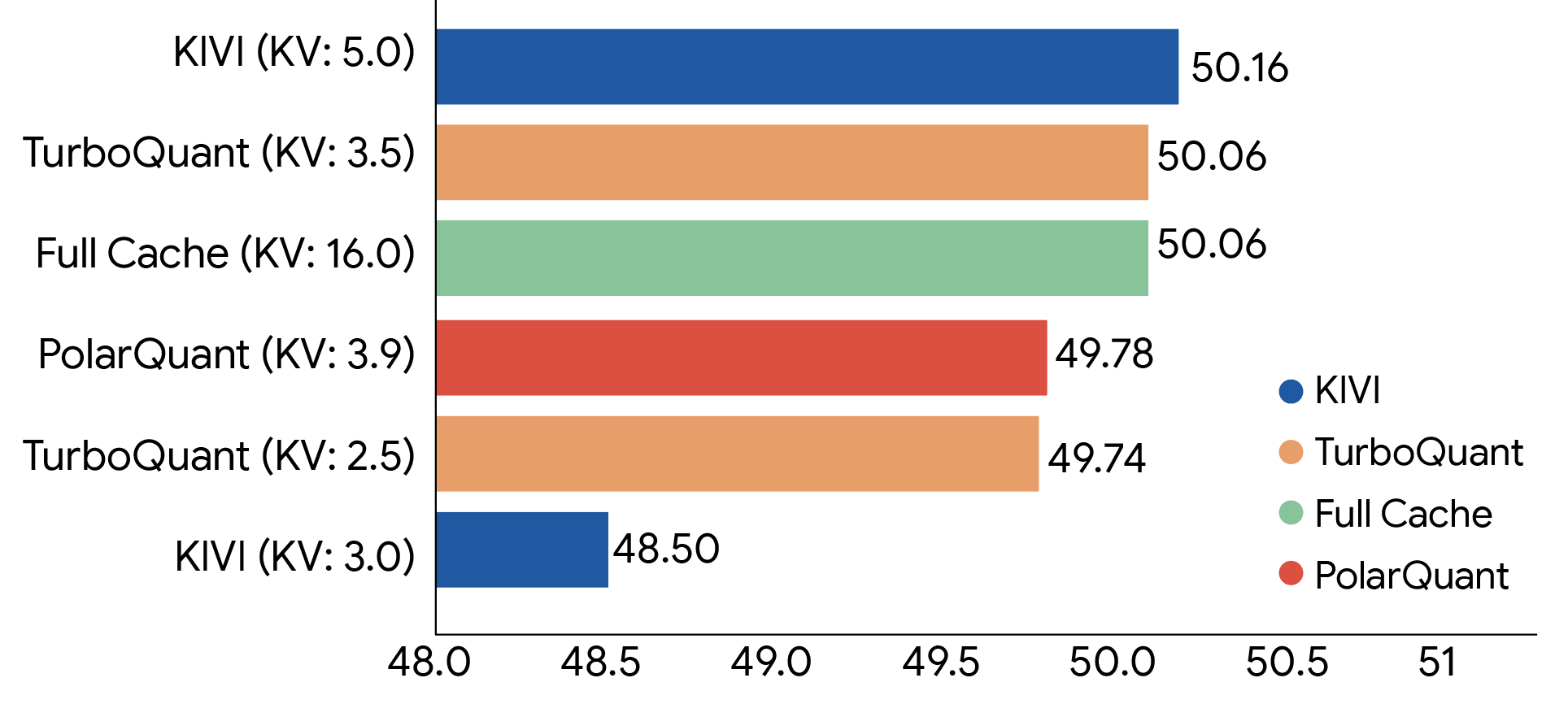
사진3: KV 캐시 양자화 기법별 LongBench 정확도 비교. TurboQuant는 3.5비트 압축에서도 16비트 Full Cache와 동일한 성능(50.06)을 유지한다. (출처 : Google Research)
기술적으로는 극좌표 변환으로 정규화 오버헤드를 제거하는 PolarQuant와, 잔차를 1비트로 압축하면서 어텐션 정확도를 유지하는 QJL의 2단계 구조로 이루어져 있습니다. 또한, 이론적 압축 손실률 하한선에 상수배(약 2.7배) 이내로 근접한다는 수학적 보장도 갖추고 있습니다.
물론 실제 서빙 프레임워크 통합 등 프로덕션 레벨의 검증은 아직 남아있습니다. 그럼에도 이 기술이 주목받는 이유는 타이밍에 있습니다. 에이전트 AI(Agentic AI) 시대로 진입하며, 모델이 추론 과정에서 감당해야 할 '중간 상태(Intermediate states)' 데이터는 기하급수적으로 팽창하고 있습니다. 이 연구가 알고리즘 생태계에 던지는 진짜 시그널은 바로 여기에 있습니다.
지금까지 모델 경량화는 성능 저하를 감수해야 하는 '타협'이었습니다. 그러나 TurboQuant는 거대 모델의 지능 훼손 없는 극단적 압축이 수학적으로 가능함을 증명했습니다. 압축 기술이 단순한 비용 절감 수단을 넘어, 다가올 AI 서비스의 생존을 결정짓는 핵심 무기로 격상되었음을 최전선에서 선언한 셈입니다.
시그널이 가리키는 한 곳
세 가지 시그널을 나란히 놓겠습니다.
30개 이상의 기관이 "향후 10년의 핵심은 효율 1000배 개선이며, 양자화·가지치기·모델 압축이 핵심 레버"라고 선언했습니다. NVIDIA는 하드웨어 자체를 4비트 네이티브로 재설계하고, '와트당 토큰'을 AI 경제의 새로운 단위로 내세웠습니다. Google의 TurboQuant는 아직 프레임워크 통합도 안 된 연구 단계임에도, 공개 직후 반도체 시가총액 수조 원을 움직였습니다.
비전, 하드웨어, 알고리즘. 이 세 층이 모두 한 곳을 가리키고 있습니다.
이것은 몇몇 연구자의 관심사가 아닙니다. AI 산업의 무게중심이 이동하고 있다는 구조적 증거입니다.
지금까지 AI 경쟁은 '누가 더 많은 GPU를 확보하느냐'의 게임이었습니다. 그 전제는 여전히 유효합니다. 하지만 1 기가와트라는 고정된 전력 상한선 아래에서는 이야기가 달라집니다. 앞으로의 승부는 확보한 인프라 위에서 모델의 밀도(density)와 에너지 효율을 극한까지 끌어올리는 기술력에 달려 있습니다.
참조
[1] AI+HW 2035: Shaping the Next Decade — Deming Chen, Jason Cong, et al. (2026)
[2] TurboQuant: Redefining AI Efficiency with Extreme Compression — Google Research Blog (2026.3)
[3] Introducing NVFP4 for Efficient and Accurate Low-Precision Inference — NVIDIA Technical Blog
[4] GTC 2026 Keynote by Jensen Huang — NVIDIA GTC San Jose (2026.3)
[5] Memory stocks fall after Google posts AI development TurboQuant — CNBC (2026.3.26)
이 연구에 대해 추가로 궁금한 사항이 있으시면 아래 이메일 주소로 언제든지 문의해 주세요: 📧 contact@nota.ai.
노타 AI의 최신 인사이트, 이제 LinkedIn에서도 만나보세요. 엣지 AI 트렌드부터 기술 업데이트까지 — Edge Insights 뉴스레터를 구독하고 가장 먼저 받아보세요. 👉 구독하기또한, AI 최적화 기술에 관심이 있으시면 저희 웹사이트 🔗 netspresso.ai.를 방문해 보세요.