[GTC 2026 총정리] 1조 달러 추론 경쟁의 시작 : 빈틈을 메우는 노타

Jaehoon Lee
Technical Content Manager, Nota AI
단순한 기술 행사를 넘어 글로벌 경제와 금융 시장까지 주목하고 있는 행사가 된 GTC. 올해도 어김없이 트레이드 마크인 가죽 재킷을 입고 무대에 오른 젠슨 황 CEO는 약 2시간에 걸친 기조연설을 통해 AI 산업의 다음 방향을 제시했습니다. 긴 연설을 관통하는 핵심 메시지를 한 문장으로 요약하면 이렇습니다.
“모델을 학습시키는 경쟁은 끝났습니다. 만들어진 모델을 실제로 돌리는 추론의 시대가 왔고, 이제 그 추론을 얼마나 깊이 있게 최적화하느냐가 승부를 가릅니다.”
이 선언이 어떤 의미를 갖는지, 또 우리는 무엇에 주목해야 할지 산호세에서 펼쳐진 나흘간의 이야기를 정리합니다.
Token Economics: 새로운 화폐의 등장
엔비디아가 제시한 2025-27년 매출 기회 전망은 기존 5,000억 달러에서 1조 달러로 올랐습니다. 이 숫자의 근거에 바로 ‘추론’이 있습니다.
1만배, 수요 폭증의 구조
젠슨 황의 발표에 따르면 지난 2년간 AI 워크로드의 연산량이 1만 배 늘었습니다. 요청과 답변이 일대일로 대응하던 챗봇 시대를 지나, 스스로 생각하고 계획하며 도구를 사용하는 에이전트 단계로 진입했기 때문입니다. 에이전트는 하나의 작업을 처리하기 위해 읽고, 판단하고, 도구를 호출하고, 검증하는 과정을 수십 번 반복합니다. 토큰 소비가 선형이 아니라 기하급수적으로 늘어나는 이유입니다.
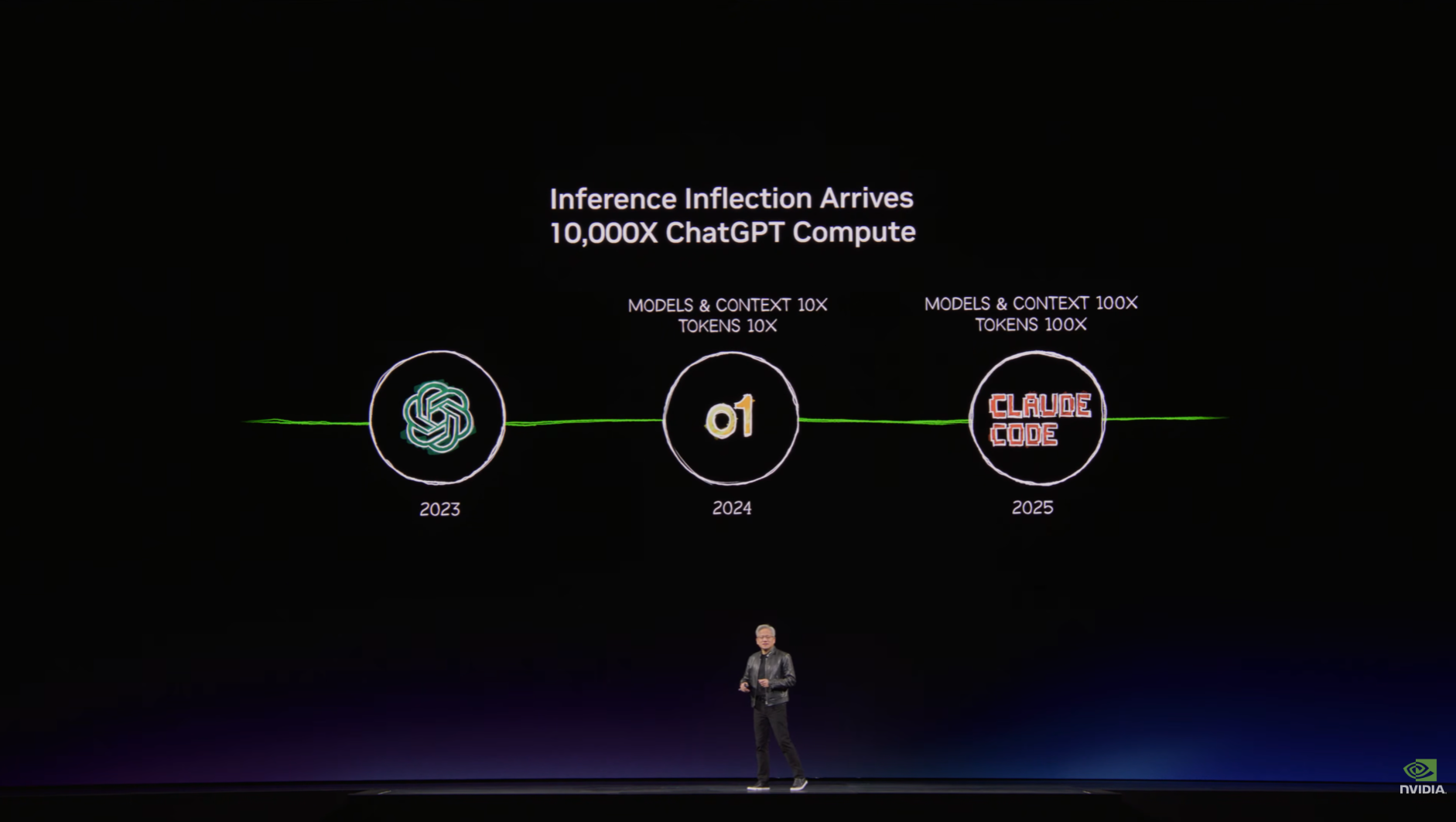
사진1: ChatGPT 등장 이후 2년간 추론 연산 수요가 1만 배 증가한 흐름을 보여주는 슬라이드 (출처: GTC 2026 키노트)
여기에 AI 에이전트를 도입하는 기업과 서비스가 빠르게 늘면서, 수요의 총량 자체가 커지고 있습니다. 결국 더 많은 토큰을, 더 적은 비용으로 찍어낼 수 있는 인프라를 가진 기업이 힘이 강해지는 구조입니다.
AI 팩토리: 데이터센터의 재정의
과거 데이터센터는 서버 수, 가동 안정성, 저장 용량으로 평가받는 비용 부서(Cost Center)였습니다. 젠슨 황이 이번에 제시한 기준은 다릅니다. 같은 전력으로 얼마나 많은 토큰을 찍어낼 수 있는지, 얼마나 빠르고 싸게 공급할 수 있는지, 더 긴 문맥과 더 복잡한 추론을 감당할 수 있는지가 데이터센터의 가치를 결정합니다. 데이터를 보관하는 곳이 아니라, 토큰을 생산하는 AI 팩토리(AI Factory)로 전환되고 있다는 선언입니다.
추론 효율을 측정하는 기준도 달라지고 있습니다. 지금까지는 초당 처리 토큰 수(throughput)가 가장 중요한 요소였다면, 이번 GTC에서는 달러당 토큰 수(tokens per dollar), 와트당 토큰 수(tokens per watt) 같은 비용 지표가 전면에 등장했습니다. 토큰을 얼마나 많이 만드느냐가 아니라, 얼마나 싸고 빠르게 만드느냐가 경쟁력이 되는 시대가 열리고 있습니다.
Agentic AI: 자유와 방임 사이
맥미니 품귀 현상을 만들어 낸 OpenClaw는 출시 2개월 만에 주간 사용자 200만 명을 달성하고, OpenAI에 인수됐습니다. 출시 8개월 만에 ARR 1억 달러를 돌파한 Manus는 메타가 약 20억 달러에 품었습니다. 글로벌 빅테크의 움직임이 한 곳을 가리키고 있습니다. AI 에이전트.
AI 에이전트, 만드는 건 쉬워졌다
OpenClaw가 보여준 건 단순한 제품의 성공이 아닙니다. 누구나 자신만의 에이전트를 만들 수 있는 시대가 열렸다는 것, 그리고 에이전트의 성능은 결국 사용자를 얼마나 잘 이해하느냐에 달려 있다는 것을 보여주었습니다. 단순히 컨텍스트 윈도우를 늘리는 것만으로는 부족합니다. 개인이나 조직의 정보를 구조화해 저장하고, 필요한 순간에 꺼내 쓸 수 있어야 합니다. 긴 문맥의 효율적 처리, 중간 연산 결과(KV-cache) 관리, 반복 작업의 재활용(Prefix Caching) 같은 기술이 중요해지는 이유입니다.
AI 에이전트에게 울타리가 필요한 이유
그러나 기업 입장에서 에이전트 도입은 여전히 쉽지 않습니다. 에이전트는 사람의 개입 없이 스스로 판단하고 행동합니다. 자유에는책임이 따르지만, AI는 아직 책임을 질 줄 모릅니다. 잘못된 판단이 곧바로 실행으로 이어지는 구조에서, 통제 없는 자유는 방임이 됩니다. 울타리가 필요한 이유이며, 엔비디아도 이 지점을 겨냥했습니다.
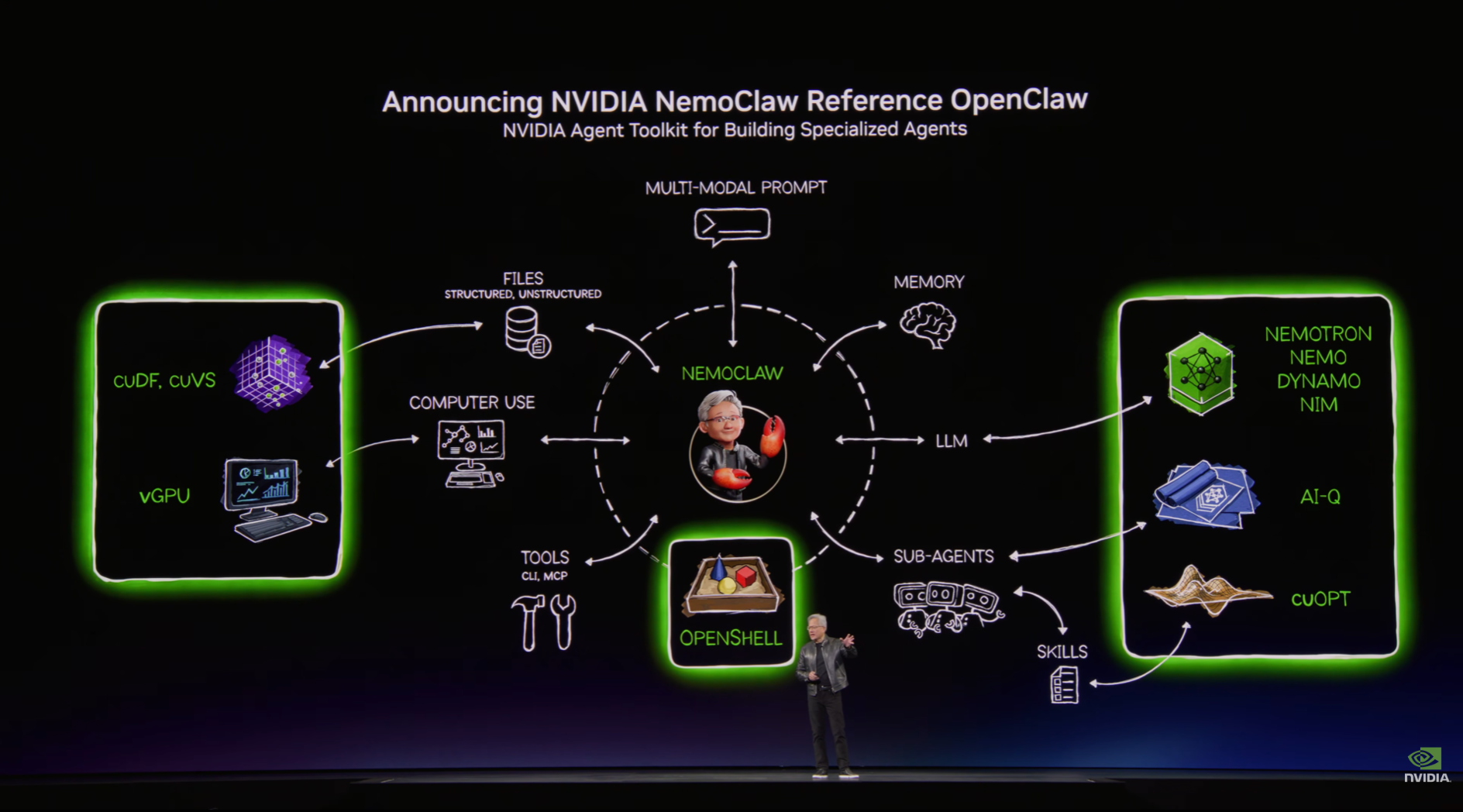
사진2: 에이전트의 생성부터 배포, 통제까지 하나로 묶은 NemoClaw 아키텍처 (출처: GTC 2026 키노트)
이번 GTC에서 엔비디아는 에이전트를 만들고, 배포하고, 통제하는 스택을 한꺼번에 내놨습니다. OpenClaw를 레퍼런스로 채택해 엔터프라이즈 환경에 최적화된 보안과 가드레일을 적용한 NemoClaw, 그리고 그 위에서 구동되는 베이스 모델 Nemotron 3 Ultra. 만드는 것, 돌리는 것, 관리하는 것을 하나의 파이프라인으로 묶은 구조입니다.
OpenAI, 메타, 그리고 엔비디아까지. AI 에이전트를 향한 빅테크의 방향은 하나로 수렴하고 있습니다. 에이전트가 동료처럼 일하는 시대, HR이 사람을 관리하듯 에이전트를 관리하는 AR (Agent Relations) 능력이 중요해질 것으로 보입니다.
Physical AI: 디지털에서 현실로
나흘간의 키노트에서 가장 많은 환호를 받으면서도, 가장 많은 것을 시사한 장면이 있었습니다. 디즈니의 올라프가 무대 위를 걸어 나온 순간입니다. 짧은 다리로 아장아장 젠슨 황에게 걸어가던 올라프의 모습은 영화 속 그 캐릭터를 떠올리게 했습니다. 놀라운 건, 이 올라프가 어떻게 걷는 법을 배웠느냐입니다.
시뮬레이션이 대체하는 현실 데이터
올라프는 현실 세계에서 훈련받지 않았습니다. GPU 기반 물리 시뮬레이터 Kamino 안에서 수천 개의 가상 환경을 동시에 돌리며, 흔들리는 배 위에서 균형 잡는 법부터 장애물을 피해 걷는 법까지 몇 시간 만에 익혔습니다. 현실 데이터를 모으는 대신, 시뮬레이션으로 합성 데이터를 대량 생산하고 병목을 연산력으로 밀어붙이는 접근입니다.
이런 현상을 두고 젠슨 황은 ‘로봇계의 GPT Moment’라는 강렬한 표현까지 던졌습니다. 자율주행에서는 BYD, 현대, 닛산이 새로 합류했고, Uber와 로보택시 파트너십을 발표했습니다. 휴머노이드 로봇에서는 GR00T N2가 기존 모델 대비 태스크 성공률 2배를 기록했고, Boston Dynamics, Figure, 1X 등이 이 플랫폼 위에서 개발을 진행하고 있습니다. 전시장을 가득 채운 로봇들이 이 흐름의 규모를 말해줍니다.

사진3: 키노트 무대 위에 모인 로봇, 자율주행 차량, 산업용 중장비 (출처: GTC 2026 키노트)
이를 뒷받침하는 기술 스택도 한층 구체화됐습니다. 엔비디아는 로봇이 현실 세계를 이해하기 위한 월드 모델 Cosmos, 시뮬레이션 환경을 구축하는 Isaac Lab, 그리고 Google DeepMind·Disney Research와 공동 개발한 오픈소스 물리 엔진 Newton을 함께 공개했습니다. 핵심 전략은 명확합니다. 실세계 데이터 수집이라는 병목을 시뮬레이션으로 우회하고, 로봇 훈련의 데이터 문제를 컴퓨팅 문제로 전환하는 것입니다. 시뮬레이션에서 학습한 정책을 현실 로봇에 이식하는 Sim-to-Real 파이프라인이 이 전략의 중심에 있습니다.
GPT Moment는 정말 왔을까?
이번 키노트에서 공개된 내용이 모델의 아키텍처와 학습 방법론 수준에 머물렀다는 점은 분명한 아쉬움으로 남습니다. 자율주행 모델 'Alpamayo'가 방향성을 제시하긴 했지만, 현재까지 보여준 모습은 혁신적인 AI라기보다는 시뮬레이션 환경에서의 정교한 제어 기술에 가깝습니다.
여기서 던져야 할 더 중요한 질문은 '이 모델이 실제 도로 위에서 얼마나 빠르게 반응하는가', 그리고 '지연 시간(latency)이 철저하게 통제되는가'입니다. 자율주행이나 로보틱스는 단 0.1초의 판단 지연조차 치명적인 사고로 직결될 수 있는 영역이기 때문입니다. 발표에서 'GPT Moment'라는 표현을 사용한 만큼, 이러한 실환경에서의 검증은 더욱 엄격해야 합니다.
과거 ChatGPT가 패러다임을 바꿀 수 있었던 이유는 누구나 즉시 사용해 볼 수 있었고, 실제 사람과 대화하는 듯한 압도적인 결과물을 보여주었기 때문입니다. 피지컬 AI가 이 수준에 도달하려면 AI가 현실 세계를 보고, 판단하고, 행동하는 전 과정이 실제 환경에서 실시간에 가깝게 구현되어야 합니다. 따라서 현재의 피지컬 AI가 진정한 의미의 'GPT Moment'에 도달했다고 보기에는 아직 이른 감이 있습니다.
Full-Stack AI: 수직으로 쌓고, 수평으로 연다
에이전트가 토큰을 대량으로 소비하고, AI가 현실 세계로 나간다는 것. 이 자체로는 기술 업계에서 충분히 예상 가능한 시나리오였습니다. 문제는 이를 떠받칠 인프라입니다. 최적화해야 할 계층은 늘어나고, 각 계층이 요구하는 조건은 점점 달라지고 있습니다. 엔비디아가 이번 GTC에서 스스로를 GPU 기업이 아닌 Full-Stack AI 기업으로 선언한 배경입니다.
Vera Rubin: 칩부터 모델까지
젠슨 황은 AI 인프라를 다섯 개 층의 케이크에 비유했습니다. 에너지, 칩, 인프라, 모델, 애플리케이션. 엔비디아는 이 다섯 층을 모두 쥐고 있습니다. 맨 아래 전력 효율을 좌우하는 GPU 아키텍처부터, 추론 파이프라인을 관리하는 소프트웨어 스택, 그 위에서 돌아가는 자체 모델(Nemotron)과 에이전트 프레임워크(NemoClaw)까지. 한 기업이 칩부터 애플리케이션까지 수직으로 통합한 구조입니다.
이 비전을 하드웨어로 구현한 것이 Vera Rubin 플랫폼입니다. Vera CPU와 Rubin GPU를 결합한 풀스택 아키텍처로, 단일 랙에 3.6 엑사플롭스의 연산력을 집약했습니다. 여기에 약 200억 달러에 인수한 Groq의 기술을 더해, 추론 과정을 프리필(Prefill)과 디코드(Decode)로 물리적으로 분리했습니다. 연산 집약적인 프롬프트 처리는 GPU가, 토큰을 하나씩 생성하는 디코드는 전용 LPU가 맡습니다. 추론을 하나의 덩어리가 아니라 단계별로 쪼개 최적화할 수 있다는 것을 아키텍처 수준에서 보여준 셈입니다.

사진4: 프리필을 담당하는 Rubin GPU와 디코드를 담당하는 Groq 3 LPU의 역할 분리 구조(출처: GTC 2026 키노트)
흥미로운 건 이 수직 통합이 폐쇄적이지 않다는 점입니다. 엔비디아는 이번에 언어, 비전, 로보틱스, 자율주행, 생명과학, 그래픽에 이르는 여섯 가지 모델 패밀리를 공개했습니다. 모델은 누구나 쓸 수 있게 열되, 그 모델이 가장 잘 돌아가는 하드웨어와 추론 인프라는 엔비디아가 쥐는 구조입니다. AWS, Azure, Google Cloud 같은 주요 클라우드 파트너와도 깊이 결합합니다. 젠슨 황의 표현을 빌리면, "수직으로 통합하되 수평으로 개방하는(vertically integrated, horizontally open)" 전략입니다.
통제된 스택 너머의 현실
엔비디아는 자사 칩과 소프트웨어 스택 사이의 수직적 최적화에 있어 이미 독보적인 위치에 있습니다. GPU 아키텍처에 맞춰 CUDA, TensorRT, NIM을 설계하고 그 위에 모델까지 온전히 얹어냅니다. 통제된 환경 안에서 성능을 최대치로 끌어올리는 것, 이는 엔비디아가 보여준 극한 통합(extreme codesign)의 정수라 할 수 있습니다.
그러나 이 최적화는 철저히 엔비디아 스택 안에서 완결됩니다. 통제된 데이터센터를 벗어나, 실제 현장의 파편화된 엣지 디바이스들이 요구하는 각기 다른 전력, 메모리, 요구 지연시간등의 제약 조건까지는 반영되지 않습니다. 여섯 가지 모델 패밀리를 오픈소스로 공개하며 생태계를 확장하고 있지만, 완성된 모델을 각기 다른 하드웨어 환경에 맞춰 온전히 구동시키는 것은 완전히 다른 영역의 문제입니다. AI의 성장세는 폭발적이지만, 현실적으로 이 인프라가 본격적인 수익을 만들어낸 곳은 아직 데이터센터 한 곳뿐인 이유입니다.
모바일, 자동차, 로보틱스, IoT. 이 시장들이 열리려면, 각 현장의 디바이스 조건과 사용 패턴에 맞는 최적화가 선행되어야 합니다. 결국 AI 생태계에 남아 있는 마지막 과제는, 통제된 스택을 넘어 현장의 복잡한 변수까지 모두 아우르는 완전한 통합(complete codesign)입니다.
노타(Nota AI): 빈틈을 채워온 팀
엔비디아가 소개한 Vera Rubin과 같은 거대 인프라는 훌륭한 기반이지만, 대중의 시선은 이미 서버를 넘어 엣지 단에서의 활용으로 향하고 있습니다. 그러나 대중이 머무는 실제 현장의 조건은 완전히 다릅니다. 자동차의 ECU, 공장의 카메라 센서, 로봇 등 AI가 실제로 작동해야 할 환경은 전력도, 메모리도, 공간도 턱없이 제한적입니다.
이 문제를 풀어온 기업이 바로 노타입니다. 일찍이 모델 경량화와 하드웨어별 최적화에 포커스를 두고 넷츠프레소(NetsPresso®)를 만들었습니다. 핵심은 '범용 압축'이 아니라 '조건부 최적화'입니다. 같은 모델이라도 올라갈 칩, 허용되는 지연 시간, 전력 제약에 따라 최적화 전략이 달라집니다. 노타의 이러한 기술력은 단순한 이론에 머물지 않습니다. 다양한 글로벌 팹리스 및 빅테크 기업들과 쌓아온 레퍼런스가 이를 증명합니다. 대표적인 사례를 소개합니다.
삼성전자: 차세대 모바일 AP '엑시노스 2600'에 AI 최적화 기술을 공급하며 온디바이스 생성형 AI 대중화를 이끌고 있습니다.
퓨리오사AI: 2세대 NPU 'RNGD'의 추론 성능 최적화를 위한 플랫폼을 공급하며, 모바일 및 차량용 AP는 물론 AI 서버와 데이터센터 반도체 영역까지 폭넓게 아우르고 있습니다.
복잡한 현장의 조건에 맞춰 최적화하는 것, 이것이 바로 노타가 가장 잘해온 일입니다. 노타는 엔비디아가 직접 닿기 어려운 엔드유저(End-user) 고객과 밀접하게 연결되어 완전한 최적화를 제공하며, 기술과 현장 사이의 빈틈을 견고하게 채우고 있습니다.
마무리: 하나의 질문으로 수렴하는 세 가지 전환
토큰 경제, 에이전틱 AI, 피지컬 AI. 이번 GTC에서 선언된 세 가지 전환은 각각 다른 이야기처럼 보이지만, 결국 같은 질문으로 수렴합니다. 거대한 모델을, 제한된 환경에서, 성능을 지키면서 어떻게 돌릴 것인가.
데이터센터에서는 와트당 토큰 수(tokens per watt)가 경쟁력을 가르고, 에이전트는 수십 번의 추론을 반복하며, 로봇은 0.1초 안에 판단을 내려야 합니다. 장소와 형태는 다르지만, 추론 효율이라는 본질은 같습니다.
노타가 풀어온 질문이 바로 그것입니다. 모든 환경에서 AI가 작동하는 세상을 만드는 일. GTC가 보여줬듯, 그 무대는 점점 넓어지고 있습니다.
이 연구에 대해 추가로 궁금한 사항이 있으시면 아래 이메일 주소로 언제든지 문의해 주세요: 📧 contact@nota.ai.또한, AI 최적화 기술에 관심이 있으시면 저희 웹사이트 🔗 netspresso.ai.를 방문해 보세요.