NotaMoEQuantization: Solar-Open-100B에 적용된 MoE 구조 특화 양자화 방법론

Hancheol Park, Ph. D.
AI Research Engineer, Nota AI

Tairen Piao
AI Research Engineer, Nota AI

Tae-Ho Kim
CTO & Co-Founder, Nota AI

✔️ Resource : K-AI 독자 파운데이션 모델 1차수 통과 모델인 업스테이지 Solar-Open-100B의 공식 양자화 모델: https://huggingface.co/nota-ai/Solar-Open-100B-NotaMoEQuant-Int4
요약
본 기술 문서에서는 노타만의 전문가 혼합 구조(Mixture-of-Experts, MoE)에 특화된 양자화 기술인 NotaMoEQuantization 대해 논의합니다.
NotaMoEQuantization을 K-AI 독자 파운데이션 모델 1차수 통과 모델인 업스테이지 Solar-Open-100B에 적용하여 효과성을 입증합니다.
MoE 구조를 고려하여 설계된 NotaMoEQuantization의 개별 세부 기법들의 효과들에 대해서도 분석합니다.
소개
최근 공개되는 대규모 언어 모델(Large Language Model, LLM)은 모든 토큰이 하나의 피드포워드 네트워크(Feed Forward Network, FFN)를 공통으로 거치는 밀집 구조(dense architecture)보다는, 혼합 전문가 구조를 점점 더 많이 채택하는 추세입니다. 혼합 전문가 구조는 여러 개의 전문가(expert) 피드포워드 네트워크를 두고, 각 토큰마다 라우터(router)가 상위 k개의 전문가를 선택한 뒤 이들의 출력을 가중 합으로 결합해 최종 출력을 만드는 방식입니다. 이런 희소 구조는 매 토큰마다 전체 파라메터를 모두 활성화하는 대신 일부 전문가만 선택적으로 활성화한다는 점이 특징입니다. 그 덕분에 전체 파라메터 수가 동일한 밀집 모델과 비교 했을 때 추론 과정에서 필요한 연산 량을 획기적으로 줄일 수 있습니다.
다만 혼합 전문가 구조가 추론 시 실제로 활성시키는 파라메터의 수를 줄여 주는 것은 사실이지만, 모델이 보유한 전체 파라메터 수 자체를 줄여 주는 것은 아닙니다. 따라서 실제 배포 환경에서는 저장 공간과 메모리 사용 효율을 높이기 위해 여전히 양자화(quantization) 같은 경량화 기법을 적용은 필수적입니다. 문제는 혼합 전문가 구조에 양자화를 적용하는 일이 기존의 밀집 구조 양자화와 동일한 관점으로 단순하게 다루기 어렵다는 점입니다.
기존 양자화 방법을 혼합 전문가 구조에 그대로 적용할 때 간과하기 쉬운 부분은, 양자화 이후 각 디코더 블록 출력이 양자화 이전 모델과 비슷하게 유지되도록 만드는 것만으로는 성능을 안정적으로 보존하기 어렵다는 사실입니다. 혼합 전문가 구조에서는 각 토큰이 어느 전문가로 전달될지를 라우터가 상위 k개 전문가를 선택하는 방식으로 결정하는데, 이 과정에서 양자화 때문에 라우터의 출력인 라우터 로짓(router logits)이 흔들리면 선택되는 전문가 집합 자체가 바뀌는 재 라우팅(rerouting)이 발생할 수 있습니다 (라우터 레이어 자체를 양자화 하지 않아도 자가 집중 레이어(self-attention)의 양자화 결과만으로도 라우팅 연산 결과에 영향을 끼칠 수 있음). 이런 재 라우팅은 단순한 연속 값 오차로 끝나는 문제가 아니라, 토큰이 지나가는 연산 경로 자체를 바꾸는 현상입니다. 그래서 블록 출력에 미치는 영향도 비선형적으로 더 크게 증폭될 수 있습니다(그림 1).
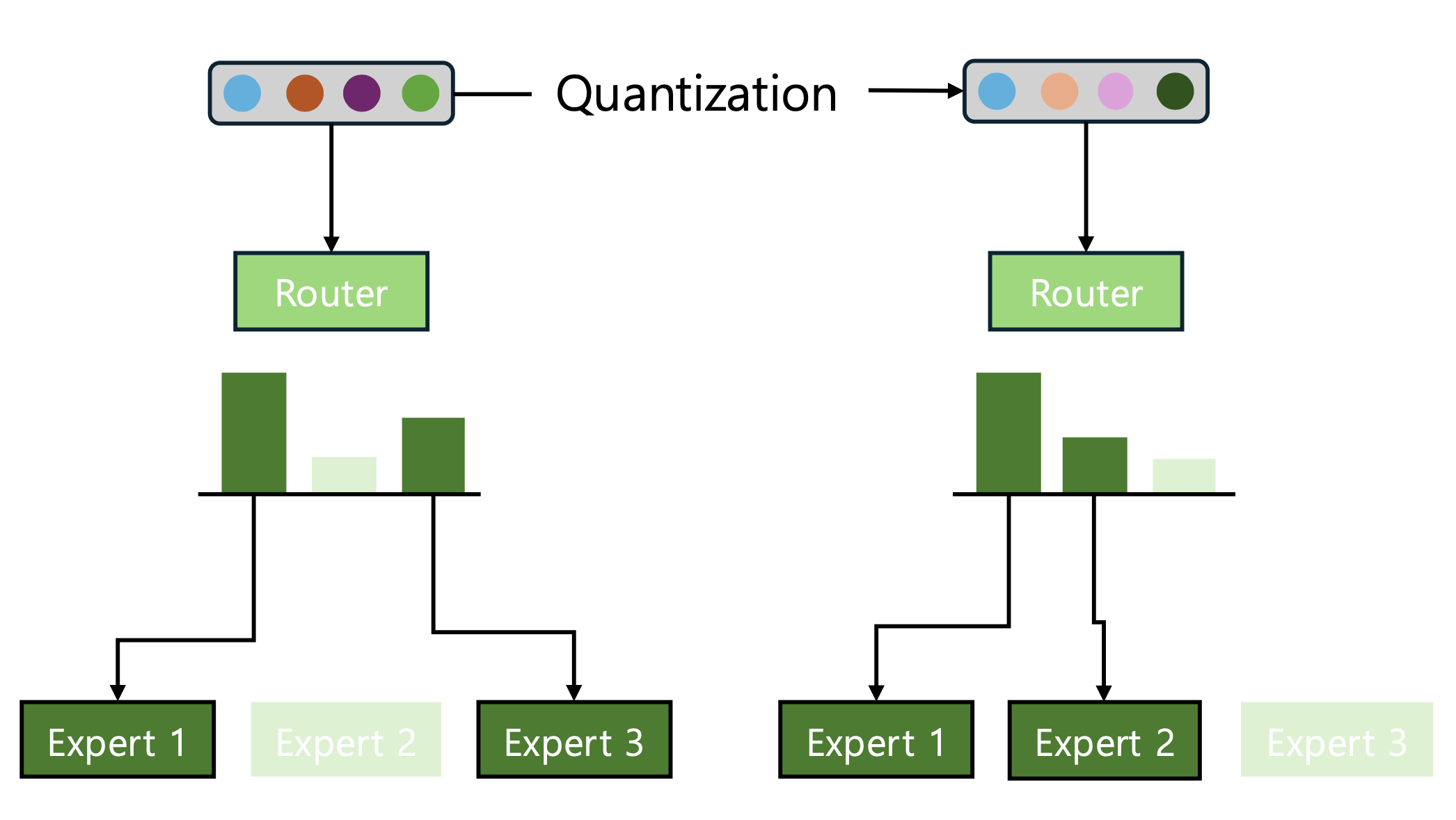
그림 1: 양자화로 인해 전문가 선택이 바뀌는 상황에 대한 도식. 위 예제에서는 양자화 이후 전문가 3 대신 전문가 2가 선택되기 때문에 출력 왜곡이 더 심하게 발생될 수 있는 상황을 묘사함
이 문제를 완화하기 위해 최근 연구에서 Chen et al. (2025)은 양자화 파라메터를 결정할 때, 상위 k개 전문가의 로짓(logits) 값이 양자화 전후에 최대한 비슷하게 유지되도록 하는 TopK-MSE 손실함수를 명시적으로 사용하는 방법론을 제안하였습니다. 그러나 단순히 top-k 전문가들에 대한 로짓 값만 일치시킨다고 선택되는 top-k가 유지되는 것을 보장할 수 없습니다. 비슷한 확률이지만 선택되지 못한 전문가들이 양자화로 인한 값의 변동 과정에서 선택될 수도 있습니다. 본 기술문서에서는 단순히 상위 k개 로짓의 값 차이를 줄이는 데서 더 나아가, 라우팅 결과 전반의 일관성을 다양한 관점에서 유지할 수 있는 Nota만의 전문가 혼합 구조에 특화된 양자화 방법을 논의합니다. 또한 대한민국 정부 주도 사업인 K-AI 독자 파운데이션 모델 프로젝트에서 1차 통과한 Upstage의 Solar-Open-100B 모델에 적용하여 해당 방법론의 효과도 함께 살펴보았습니다. 본 블로그에서 기술하는 Solar-Open-100B 양자화 모델은 Upstage Solar-Open-100B의 공식 양자화 모델로 선정되어 현재 Huggingface Hub에 공개되어 있습니다 (상기 Resource 섹션의 링크 참조).
NotaMoEQuantization (NMQ)
Nota 혼합 전문가 양자화(NotaMoEQuantization, NMQ)는 노타가 제안한 전문가 혼합 구조 전용 양자화 기법입니다. NMQ의 핵심은 양자화 이후에도 라우터가 고르는 상위 k개 전문가(top-k) 집합, 그에 대응하는 확률 또는 점수 분포, 그리고 전문가 사이의 순위와 경계 관계가 원본 모델과 최대한 같게 유지되도록 만드는 데 있습니다. 다시 말해 NMQ는 하나의 독립적인 양자화 알고리즘이라기 보다는, 양자화 파라메터나 라우터 가중치를 선택하거나 조정할 때 사용하는 손실 함수로 이해하는 편이 더 정확합니다. 이런 특성 덕분에 학습 기반 방식은 물론이고 최적화 기반 방식까지, 다양한 양자화 방법론에 플러그인(plug-in)처럼 결합해 적용할 수 있습니다.
이 기술 문서에서는 학습 기반으로 양자화 파라메터를 결정하는 오토라운드(AutoRound) (Cheng et al., 2024)에 NMQ를 결합하는 형태로 방법론을 설명합니다. 오토라운드는 소량의 보정 데이터셋(calibration datasets)을 사용해, 각 디코더 블록(decoder block) 출력(y)의 평균 제곱 오차(mean squared error, MSE) 복원 손실(reconstruction loss)을 최소화하는 방향으로 세 가지 양자화 파라메터를 학습합니다.
$$\mathcal{L}_{\text{recon}} = \|\mathbf{y}^q - \mathbf{y}^{fp}\|_2^2$$
$$y^{fp}$$ : 양자화 전 디코더 블록의 출력
$$\mathbf{y}_q$$ : 양자화 파라메터가 적용된 디코터 블록의 출력
구체적으로는 양자화 대상이 되는 텐서의 부분 블록(여기서 블록은 디코더 블록이 아니라 양자화 대상이 되는 숫자들의 집합을 의미)에 대한 스케일 인자(scale factor)를 계산하기 위해 해당 블록의 유효 최댓값과 최솟값 범위를 조정하는 α와 β, 그리고 양자화된 공간에서 반올림 방향을 조절하는 값인 V를 함께 튜닝합니다. 이렇게 각 블록은 보정 샘플을 바탕으로 복원 손실이 가장 작아지는 방향으로 양자화 파라메터를 학습하게 됩니다
혼합 전문가 구조에서는 디코더 블록의 출력 y가 라우터의 전문가 선택에 의해 직접적인 영향을 받습니다. 따라서 복원 손실만 최소화하도록 학습하면, 각 디코더 출력은 수치적으로 잘 맞더라도 정작 라우터의 선택은 뒤바뀌는 불안정한 해로 수렴할 수 있습니다. 이런 문제를 막기 위해 우리는 라우터의 로짓의 값과 구조를 보존하는 라우터 로짓 정렬 손실(router logits alignment loss)함수를 제안했습니다. 최종 손실 함수는 아래와 같이 구성되며, 이어지는 절에서는 라우터 로짓 정렬 손실의 각 요소를 차례대로 설명합니다.
$$\mathcal{L} = \mathcal{L}_{\text{recon}} + \lambda \mathcal{L}_{\text{router}}$$
(1) Value alignment loss
라우터 로짓 정렬 손실의 첫 번째 축은 값 정렬입니다. 여기서는 양자화 전후의 상위 k개 후보군이 얼마나 비슷한 값을 유지하는지를 맞추는 데 초점을 둡니다. 앞으로 설명할 손실함수에서 사용될 로짓의 표기법은 다음과 같습니다.
$$\mathbf{z}^{fp}$$ : 양자화 전 라우터의 로짓
$$\mathbf{z}_q$$ : 양자화 파라메터가 적용된 라우터의 로짓
(1-1) Top-k logits alignment loss
가장 직관적인 값 정렬 방식은, 양자화 이전에 상위 k개에 해당하던 로짓 값을 양자화 이후에도 최대한 같게 유지하도록 직접 맞추는 것입니다. 이를 위해 우리는 기존 연구와 마찬가지로 TopK-MSE 손실을 사용합니다.
$$\mathcal{L}_{\text{TopK-MSE}} = \|\mathbf{z}_{1:k}^q - \mathbf{z}_{1:k}^{fp}\|_2^2$$
여기서 1:k는 전체 전문가의 로짓을 큰 값부터 정렬했을 때, 1위부터 k위까지에 해당하는 전문가의 인덱스를 의미합니다. 이렇게 상위 k개만 맞추는 이유는 분명합니다. 라우터의 실제 의사결정은 상위 후보군 안에서 이루어지므로, 선택되지 않는 하위 전문가의 로짓까지 강하게 맞출 필요는 없기 때문입니다. 오히려 전체 전문가의 로짓을 모두 줄이도록 학습하면, 중요하지 않은 하위 로짓까지 손실을 낮추는 데 자원이 소모되어 기울기 예산(gradient budget)이 낭비될 수 있고, 결과적으로 상위 k개 구조를 복원하는 데 불리해질 수 있습니다.
(1-2) Sigmoid-aware alignment loss
한편 최근의 혼합 전문가 모델, 예를 들어 DeepSeek이나 Nemotron 계열을 포함한 여러 최신 모델은 라우터 로짓을 소프트맥스(softmax)로 한 번에 정규화하기보다, 시그모이드(sigmoid)로 먼저 값을 압축한 뒤 추가적으로 해당 값들을 0과 1사이의 값으로 정규화하는 방식을 사용합니다. 이러한 정규화 과정을 통해 각 전문가들이 선택될 확률 분포를 생성합니다. 시그모이드를 사용하는 최신 모델들의 설계에는 나름의 이유가 있습니다. 소프트맥스는 여러 전문가의 점수를 한 번에 정규화하기 때문에, 특정 전문가의 점수가 조금만 높아져도 다른 전문가들의 점수는 상대적으로 더 빠르게 작아질 수 있기 때문입니다. 그 결과 학습 초기에 일부 전문가만 반복적으로 선택되고, 다른 전문가들은 충분한 학습 기회를 얻지 못하는 현상이 생길 수 있습니다. 반면 시그모이드 기반 라우팅은 각 전문가의 점수를 보다 독립적으로 다루기 때문에, 특정 전문가로 점수가 과도하게 몰리는 현상을 줄이고 여러 전문가가 좀 더 고르게 학습될 수 있도록 돕습니다. 이런 특성 때문에 시그모이드 기반 라우팅은 이론적으로 전문가 혼합 모델 학습에 있어 더 높은 샘플 효율을 가질 수 있고, 실제로도 라우팅 안정성과 전문가 활용도 측면에서 장점이 보고되고 있습니다. 다만 시그모이드의 도입은 양자화 관점에서 새로운 민감도를 만듭니다.
시그모이드를 통과한 값이 0.5 부근에 있을 때는, 작은 로짓 변화도 시그모이드 이후 값에서는 더 크게 드러날 수 있습니다. 따라서 시그모이드 적용 후 값이 0.5 근처의 민감 구간에 놓인 경우일수록, 양자화 전후 로짓을 더 강하게 일치시키도록 가중치를 주는 것이 바람직합니다. 이를 위해 아래와 같은 손실함수를 제안했습니다.
$$p^{fp} = \sigma(\mathbf{z}_{1:k}^{fp}), \quad p^q = \sigma(\mathbf{z}_{1:k}^q)$$
$$w = (p^{fp}(1 - p^{fp}))^\gamma + \varepsilon_w$$
$$\mathcal{L}_{\text{sig-aware}} = \mathbb{E} \left[ w \odot (p^q - p^{fp})^2 \right]$$
여기서 가중치(w)는 로짓에 시그모이드를 적용한 값인 p가 민감 구간(0.5)에 가까워질수록 더 커지도록 설계되었으며, 추가되는 ϵ은 시그모이드 인지 가중치(sigmoid-aware weight)의 수치적 안정성을 위한 최소 바닥 값 역할을 합니다.
(1-3) Total value alignment loss
최종적인 값 정렬 손실은 앞서 소개한 두 손실, 즉 상위 k개 로짓 정렬 손실과 시그모이드 민감도를 반영한 정렬 손실을 함께 섞어 구성합니다. 다시 말해 양자화 전후 단순한 값 차이만 고려하는 것이 아니라, 실제 라우터가 민감하게 반응하는 구간에서의 차이를 더 중요하게 다루도록 설계한 것입니다.
$$\mathcal{L}_{\text{value}} = (1 - \alpha)\mathcal{L}_{\text{TopK-MSE}} + \alpha\mathcal{L}_{\text{sig-aware}}$$
(2) Structure alignment loss
두 번째 축은 구조 정렬입니다. 값 정렬이 상위 k개 로짓의 수치적 유사성을 맞추는 데 초점을 둔다면, 구조 정렬은 라우팅 안정성이 값 자체뿐 아니라 상대적인 구조에도 크게 의존한다는 점에 주목합니다. NMQ는 이 구조를 크게 두 관점에서 다룹니다. 하나는 상위 k개 내부에서 순위가 유지되는지, 다른 하나는 k번째를 기준으로 한 경계 마진이 보존되는지입니다.
(2-1) Top-k order preservation
먼저 상위 k개 순위 보존은, 양자화 이전에 1위부터 k위 까지 였던 전문가들의 상대적 순서가 양자화 이후에도 그대로 유지되도록 만드는 것입니다. 이를 위해 우리는 순위 손실(rank loss)을 도입합니다.
$$\mathcal{L}_{\text{rank}} = \mathbb{E} \left[ \text{softplus} \left( m - (z_i^q - z_{i+1}^q) \right) \right]$$
여기서는 순위 마진(rank margin)으로, 단순히 순서만 유지하도록 하는 규제가 됩니다. 또 소프트플러스(softplus)는 렐루(ReLU) 활성화 함수의 매끄럽고 미분 가능한 근사 함수로, 인접한 두 로짓과의 차이가 보다 충분히 크면 페널티가 거의 없고, 그렇지 못하면 손실이 커지도록 만듭니다. 즉, 단순히 순서만 유지하는 수준을 넘어 일정한 여유 폭까지 확보하도록 유도하는 셈이 됩니다.
(2-2) Boundary preservation (k vs k+1:k+n 경계 보존)
다음은 경계 보존입니다. 재라우팅이 가장 자주 일어나는 지점은 상위 k개의 경계, 즉 k번째 후보와 그 바로 바깥에 있는 후보들 사이의 컷오프 부근입니다. 특히 k번째와 k+1번째, 혹은 일반적으로 k+n번째 사이의 마진이 무너지면 선택되는 전문가 집합이 쉽게 바뀔 수 있습니다. 경계 주변의 점수 차이를 보존하는 것은 라우팅 안정성을 확보하는 데 매우 직접적인 역할을 합니다. n은 k 근처의 후보들을 살펴보기 위한 작은 정수로 설정합니다.
$$\Delta_j^{fp} = z_k^{fp} - z_{k+j}^{fp}, \quad \Delta_j^q = z_k^q - z_{k+j}^q \quad (j = 1, \dots, n)$$
$$\mathcal{L}_{\text{margin}(k:k+n)} = \|\boldsymbol{\Delta}^q - \boldsymbol{\Delta}^{fp}\|_2^2$$
$$\mathcal{L}_{\text{margin}(k:k+n)} = \frac{1}{n} \sum_{j=1}^n \|\Delta_j^q - \Delta_j^{fp}\|_2^2$$
(2-3) Total structure alignment loss
전체 구조 정렬 손실은 값 정렬 손실과 마찬가지로, 상위 k개 순위 보존 손실과 경계 보존 손실을 가중 합하는 방식으로 구성합니다. 이때 wrank와 wmargin은 각각 순위 보존과 경계 보존 항의 중요도를 조절하는 가중치입니다.
$$\mathcal{L}_{\text{struct}} = w_{\text{rank}}\mathcal{L}_{\text{rank}} + w_{\text{margin}}\mathcal{L}_{\text{margin}(k:k+n)}$$
(3) Router logits alignment loss
마지막으로, 최종 라우터 로짓 정렬 손실은 값 정렬 손실과 구조 정렬 손실을 함께 묶은 형태로 정의됩니다. 즉, 상위 후보군의 로짓 값을 비슷하게 유지하는 것뿐 아니라, 그 안의 순서와 경계까지 함께 보존함으로써 양자화 이후에도 라우터의 의사결정 구조가 최대한 흔들리지 않도록 만드는 것이 이 손실 함수의 핵심입니다.
$$\mathcal{L}_{\text{router}} = \mathcal{L}_{\text{value}} + \mathcal{L}_{\text{struct}}$$
실험
NMQ의 효과를 확인하기 위해 우리는 앞서 언급한 바와 같이 오토라운드를 베이스라인(baseline) 양자화 기법으로 상정하여 구현 및 실험을 진행했습니다. 상세한 실험 세팅은 아래와 같습니다.
실험 설정
실험에 사용된 최신 전문가 혼합 모델로 우리는 Upstage의 Solar-Open-100B를 사용합니다. Solar Open 100B는 업스테이지의 대표 오픈 모델로, 102B 규모의 MoE 아키텍처와 19.7조 토큰 학습 스케일을 바탕으로 한국 오픈 LLM의 수준을 한 단계 끌어올린 모델입니다. 특히 독자 AI 파운데이션 모델 흐름 속에서, 자체 설계와 대규모 학습 역량을 갖춘 모델이 나올 수 있음을 보여준 상징적인 사례로 볼 수 있습니다. 양자화 방식은 W4A16, 즉 INT4 가중치 전용(weight-only) 양자화와, 가중치와 활성값(activation)을 함께 양자화하는 NVFP4를 사용합니다.
양자화 성능 평가는 크게 두 관점에서 진행합니다. 첫 번째는 복잡한 추론 과정을 거쳐야 하므로 긴 토큰 생성을 요구하는 장문 추론 벤치마크(long-reasoning benchmarks) 기반 평가이고, 두 번째는 비교적 짧은 정답 생성 중심의 일반 성능 벤치마크(general evaluation benchmarks) 기반 평가입니다. 장문 추론 벤치마크로는 MMLU-Pro와 GPQA-Diamond를 사용하며, 이때 추론 토큰(thinking budget)은 8,192으로 설정합니다. 일반 성능 벤치마크로는 ARC-C, ARC-E, BoolQ, HellaSwag, MMLU, PIQA, TruthfulQA, WinoGrande, GSM-8K를 사용합니다. 전체 성능은 이들 벤치마크 점수의 평균으로 측정합니다. 또한 추가적인 성능 지표로 WikiText-2 기반의 perplexity (PPL)도 함께 평가합니다.
오토라운드와 여기에 NMQ를 결합한 방법까지, 실험에 사용한 모든 방법은 Nota의 경량화 플랫폼인NetsPresso®를 활용해 구현하였습니다.
실험 결과
표 1, 2에서 확인할 수 있듯이, NMQ는 모든 벤치마크 결과에서 베이스라인 대비 일관된 성능 향상을 보였습니다. 4비트 양자화에서는 단순한 응답 생성을 주로 평가하는 일반 성능 벤치마크의 경우 원래 성능 저하 자체가 크지 않기 때문에 개선 폭도 상대적으로 작게 나타납니다. 그러나 더 깊은 추론을 요구하는 장문 추론 벤치마크에서는 훨씬 더 뚜렷한 성능 차이가 관찰되었습니다.
이런 차이는 응답 생성 과정의 특성 차이로도 설명할 수 있습니다. 짧은 응답을 생성하는 경우에는 일부 토큰에서 전문가 선택이 다소 달라지더라도 그 영향이 제한적인 수준에서 끝날 가능성이 큽니다. 반면 긴 추론 과정에서는 각 단계의 라우팅 결정이 이후 표현 형성과 다음 토큰 예측에 연속적으로 영향을 미치게 됩니다. 따라서 초기에 발생한 작은 전문가 선택 차이도 생성이 진행될수록 점차 누적되며 더 큰 차이로 이어질 수 있습니다. 이런 관점에서 보면, 양자화 전후의 전문가 선택 일관성을 더 잘 보존하는 방법이 장문 추론 벤치마크에서 상대적으로 더 큰 성능 이점을 보였을 가능성이 큽니다. 다시 말해 NMQ의 효과는 단순히 개별 토큰 수준의 오차를 줄이는 데 그치지 않고, 긴 생성 과정 전체에서 라우팅 안정성을 유지하는 데서 더 크게 드러난다고 해석할 수 있습니다.
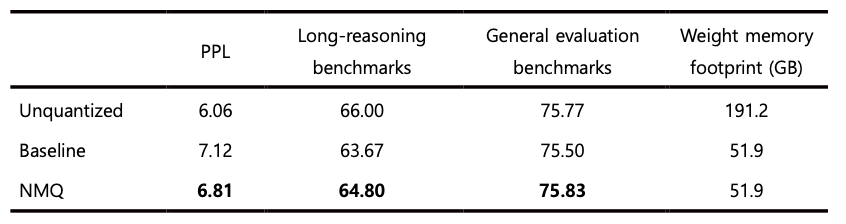
Table 1: Benchmarking results for Solar-Open-100B W4A16 quantization
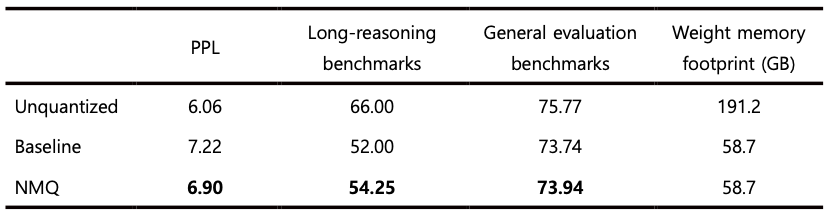
Table 2: Benchmarking results for Solar-Open-100B NVFP4 quantization
고찰
(1) NMQ의 각 손실 함수들은 효과가 있는가?
표 3에서 확인할 수 있듯이, Solar-Open-100B의 W4A16 양자화 결과에서는 최종 값 정렬 손실만 적용했을 때가 약간 더 좋은 성능을 보이기도 했습니다. 다만 전체적으로 보면 각 손실 함수를 단계적으로 추가할수록 PPL이 낮아지는 경향이 뚜렷하게 나타났습니다. PPL은 낮을수록 더 좋은 성능을 의미하므로, 이런 결과는 우리가 제안한 각 손실 항이 전반적으로 효과적으로 작동했음을 보여줍니다. 다시 말해 NMQ를 구성하는 개별 손실 함수들은 서로 다른 측면에서 양자화 오차를 보완하면서, 전체 모델 품질 개선에 실질적으로 기여했다고 해석할 수 있습니다.
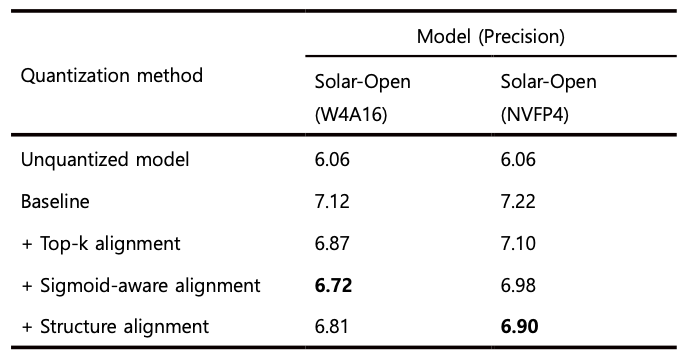
Table 3. Changes in WikiText-2 PPL when applying each loss term of NMQ
(2) NMQ는 양자화 전에 선택된 전문가를 얼마나 유지시키는데 도움을 주는가?
다음으로, NMQ가 양자화 이전에 선택되던 전문가를 실제로 얼마나 잘 유지하는지도 함께 살펴보았습니다. 이를 위해 각 레이어에서 양자화 전후에 토큰별로 선택되는 전문가 집합이 얼마나 일치하는지를 측정했습니다. 실험에는 Nemotron-Post-Training-Dataset-v2의 stem, chat, math, code 데이터를 사용했으며, 총 616,759개의 토큰을 양자화 전후 모델에 각각 통과시킨 뒤 선택된 상위 k개 전문가(top-k experts)에 대해 자카드 유사도(Jaccard similarity)를 계산했습니다. 그림 2에서 볼 수 있듯이, 모든 레이어에서 베이스라인 대비 NMQ를 적용했을 때 양자화 전후에 선택된 전문가 집합의 일치도가 더 높게 나타났습니다. 가장 큰 차이가 난 경우에는 NMQ가 베이스라인보다 11.29% 이상 높은 일치도를 보였습니다. 이는 NMQ가 단순히 출력 오차를 줄이는 데 그치지 않고, 실제 라우팅 결정 자체를 더 안정적으로 보존하는 데에도 효과적이라는 점을 보여줍니다.
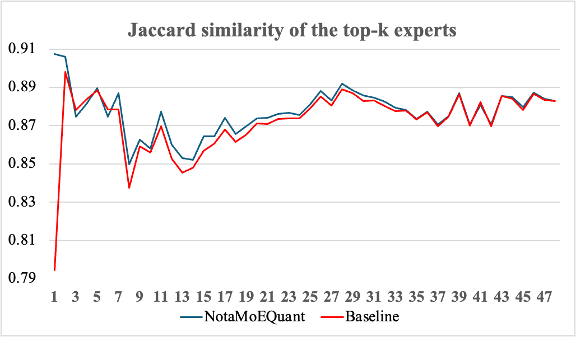
그림 2: Solar-Open-100B W4A16 양자화 후 각 레이어 별 전문가 선택에 대한 양자화 전 모델과의 일치도
(3) NMQ 이후 지연 시간(latency) 개선 정도
마지막으로, NMQ 적용 이후의 지연 시간 개선 효과도 함께 평가했습니다. 특히 이번 실험에서는 NVFP4의 하드웨어 가속 효과까지 함께 확인하기 위해 블랙웰(Blackwell) 구조의 NVIDIA B300 SXM6 환경에서 측정을 진행했습니다. 지연 시간 측정 프레임워크로는 vLLM을 사용해 수행했으며, 사용자당 입력 토큰과 출력 토큰 수는 각각 30,000개로 설정했고, 동시 요청 수(concurrency)는 8과 16인 조건에서 속도를 측정하였습니다. 표 4에서 보이듯이 모든 양자화 방식에서 의미 있는 속도 개선이 나타났고, 그 중에서도 NVFP4는 W4A16 대비 첫 토큰 생성 시간(TTFT)이 거의 2배 가까이 개선된 점이 특히 눈에 띄는 것을 확인할 수 있습니다.
이 결과는 NVFP4의 가속 효과가 특히 긴 입력 구간에서 더 크게 나타날 수 있음을 시사합니다. 입력 길이가 길어질수록 프리필(prefill) 구간이 전체 연산에서 차지하는 비중이 커지는데, NVFP4는 이런 대규모 병렬 연산에서 더 높은 효율을 제공하기 때문에 TTFT 개선으로 이어졌을 가능성이 큽니다. 즉, NVFP4의 이점은 단순히 이론적인 비트 수 절감에 머무르지 않고, 실제 장문 입력 환경에서 체감 가능한 지연 시간 감소로 연결될 수 있다는 의미를 가집니다.
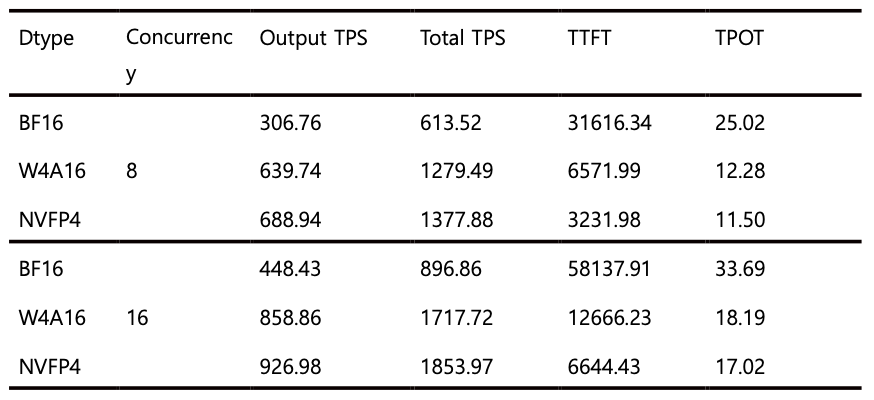
Table 4. Latency measurements of models quantized using NMQ
• TPS: Tokens per second (token throughput)
• TTFT: Mean time to first token (ms)
• TPOT: Mean time per output token (ms)
결론
이번 테크블로그에서는 NMQ를 바탕으로, 전문가 혼합 구조에 특화된 양자화 기법을 살펴보았습니다. 실험 결과를 통해 이 방법이 다양한 설정에서 일관된 성능 개선을 제공할 수 있음을 확인했습니다. 특히 이러한 결과는 전문가 혼합 구조의 양자화에서는 단순히 출력 복원만 잘하는 것으로는 충분하지 않으며, 라우팅 동작 자체를 얼마나 안정적으로 보존하느냐가 성능 유지에 중요한 요소가 될 수 있음을 보여줍니다.
노타는 앞으로도 더 낮은 정밀도 환경에서 NMQ의 효과를 추가로 검증할 계획입니다. 예를 들어 2비트 양자화처럼 더 극단적인 조건에서는 일반 성능 벤치마크에서도 성능 저하가 더 뚜렷하게 나타날 가능성이 큽니다. 따라서 이런 환경에서도 NMQ가 성능 저하를 얼마나 효과적으로 완화할 수 있는지 살펴보는 일이 중요합니다. 또한 NMQ를 오토라운드 뿐 아니라 다른 양자화 기법들과도 성공적으로 결합할 수 있는지 확인하는 것 역시 중요한 후속 연구 과제가 될 것입니다.
아울러 이번 실험에서 사용한 NMQ 구현은 NetsPresso®를 통해 빠른 시일 내에 공개할 예정입니다. 이를 통해 더 많은 연구자와 개발자가 실제 전문가 혼합 모델 양자화 환경에서 NMQ를 직접 적용하고 검증해볼 수 있기를 기대하고 있습니다.
References
[1] Chen et al. EAC-MoE: Expert-Selection Aware Compressor for Mixture-of-Experts Large Language Models. In Proceedings of ACL 2025.
[2] Cheng et al. Optimize Weight Rounding via Signed Gradient Descent for the Quantization of LLMs. In Proceedings of EMNLP 2024 Findings.
📧 이 연구에 대해 추가로 궁금한 사항이 있으시면 아래 이메일 주소로 언제든지 문의해 주세요: contact@nota.ai.