ERGO: 비전-언어 모델을 위한 효율적인 고해상도 이미지 이해 기술

Jewon Lee | Wooksu Shin | Seungmin Yang | Ki-Ung Song | Donguk Lim | Jaeyeon Kim | Tae-Ho Kim | Bo-Kyeong Kim
EdgeFM Team, Nota AI
✔️ 더 많은 정보 알아보기 : GitHub, ArXiv, Project Page, Demo.
✔️ 해당 논문은 ICLR 2026에 정식 채택되었습니다.
요약
효율적인 Coarse-to-Fine 파이프라인: 저해상도로 먼저 중요한 영역을 찾고, 해당 부분만 고해상도로 다시 분석하는 2단계 추론 구조를 통해 핵심 정보는 유지하면서 연산 비용을 효과적으로 줄입니다.
추론 중심 지각을 위한 보상 설계: 제안한 보상 설계를 통해, 모델은 단순한 객체 위치 정확도에만 의존하지 않고 문맥을 활용해 더 효율적으로 추론하도록 학습합니다.
더 적은 비전 토큰으로 SOTA 성능 달성: ERGO는 더 적은 비전 토큰을 사용하면서도 여러 고해상도 벤치마크에서 경쟁 기법을 능가하는 성능과 실질적인 속도 향상을 달성했습니다.

소개
대규모 비전-언어 모델(LVLM) 분야가 빠르게 발전하면서, 고해상도 이미지를 처리하는 능력은 실제 응용 환경에서 점점 더 중요해지고 있습니다. 하지만 해상도를 높이면 시각 토큰 수가 급격히 증가하고, 이는 곧 연산 오버헤드와 지연 증가로 이어집니다. 최근 등장한 “thinking with images” 계열 모델들도 시각 영역에서 직접 추론을 수행하지만, 인식 주도적(perception-driven)으로 추론합니다. 즉, 객체를 명확히 고해상도로 인식해야만 추론이 가능한 구조입니다. 이 때문에 세부 정보가 손실된 저해상도(coarse) 입력이 주어지면, 모델의 효율성과 성능이 모두 저하되는 문제가 발생합니다.
논문의 핵심 메시지
ERGO (Efficient Reasoning & Guided Observation)는 의미 있는 정보가 어디에 있을지 먼저 추론하도록 학습하는 모델입니다. 장면의 문맥 정보와 텍스트 질의를 함께 활용해, 대상 객체가 작거나 모호하더라도 과제와 관련된 영역을 효과적으로 추론합니다. 또한 강화학습(RL)을 통해 주변 맥락을 활용한 시각적 탐색을 유도함으로써, 보다 효율적이고 신뢰도 높은 시각 추론을 구현합니다.
논문의 의미와 중요성
ERGO는 고해상도 이해의 효율성을 새로운 방향으로 확장한 연구라고 볼 수 있습니다. 강화학습을 통해 시각적 탐색을 효율성 목표와 정렬하면 실제 과제 해결 능력까지 향상될 수 있음을 처음으로 입증했습니다. 특히 vLLM과 같은 프로덕션급 엔진과 호환되며, 이론적 가지치기(pruning) 기법들이 실제 환경에서 충분한 성능 향상을 제공하지 못하는 것과 달리, 최대 3배의 실제 지연 감소를 달성했다는 점에서 실용적 의미를 가집니다.
방법론 요약
ERGO는 강화학습 프레임워크 안에서 시각 처리 효율성을 중심에 두고 학습 목표를 설계했습니다. 이미지와 텍스트 질의가 주어지면, 파이프라인은 두 단계로 동작합니다. (1) 정책 모델이 사고 과정(thinking trace)와 함께 과제 관련 영역의 바운딩 박스 좌표를 예측합니다. (2) 원본 해상도로 크롭된 해당 영역을 다시 입력해 최종 답변을 생성합니다. 즉, 필요한 부분만 정밀 분석하는 구조입니다.
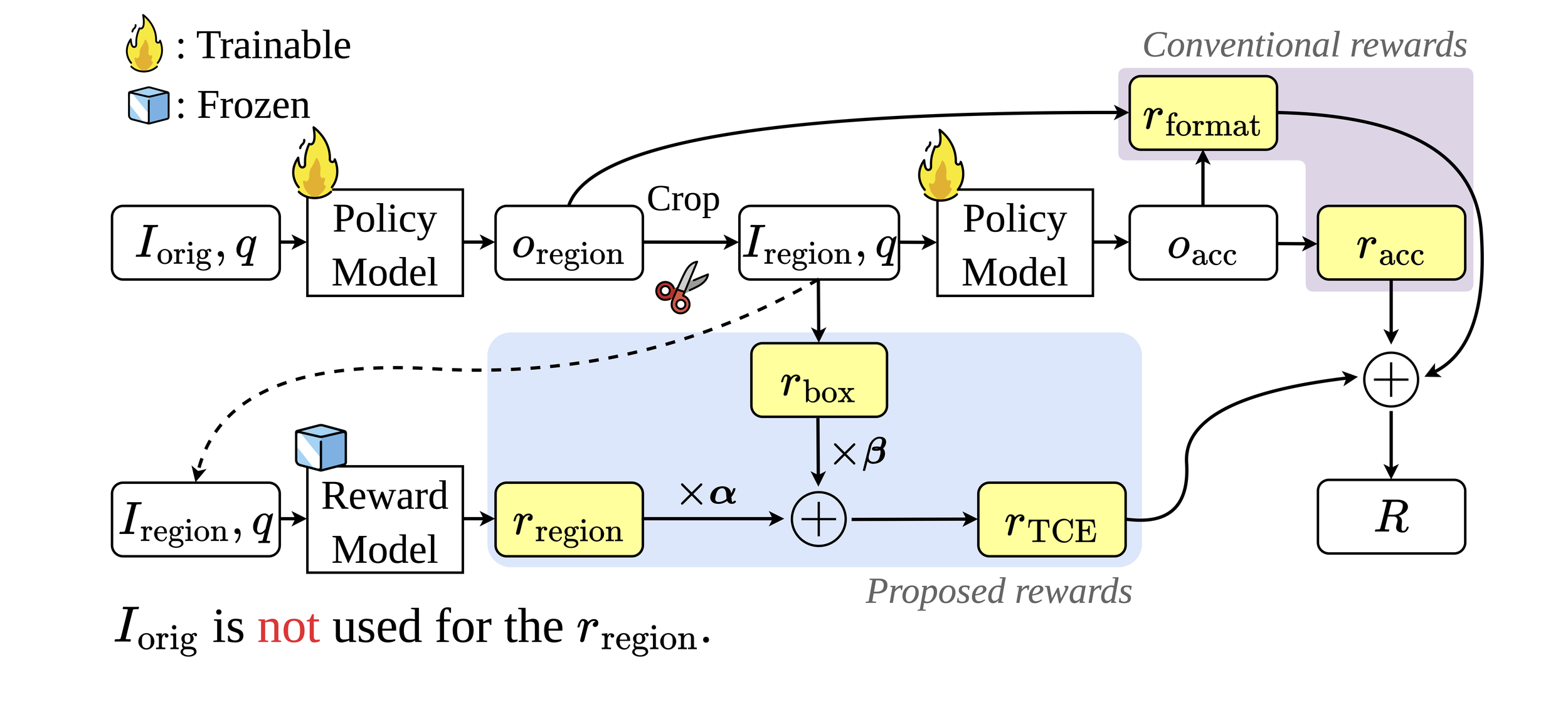
보상 설계
1. 영역 검증 보상(Region-Verification Reward)
원본 이미지 없이, 크롭된 영역과 질의만으로 과제 수행 능력을 평가합니다. 이를 통해 모델이 충분한 정보를 담은 self-contained 영역을 선택하도록 유도합니다.
2. 영역 크기 조정 보상(Box Adjustment Reward)
선택된 영역의 크기를 보완하는 보상입니다. 면적 비율에 따라 지나치게 큰 크롭에 패널티를 부여해, 전체 이미지를 그대로 선택하는 단순 전략을 방지합니다.
3. 과제 주도 맥락 탐색 보상(Task-Driven Contextual Exploration, TCE)
두 보상을 결합한 Task-Driven Contextual Exploration (TCE) 보상은 다음과 같이 정의됩니다.
의 형태로 정의되며, 정책 모델이 시각 기반 추론을 위해 보다 견고하고 효율적인 영역 선택 전략을 학습할 수 있도록 합니다.
4. 최종 보상 함수
전체 보상은 다음과 같이 선형 결합으로 구성됩니다.
여기서 r_acc는 학습-추론 간 불일치를 완화하고, r_format은 구조화된 출력 형식을 유지하도록 제약하는 역할을 합니다.
실험 결과
해당 논문에서는 ERGO의 정확도와 효율성을 검증하기 위해, 최신 모델 및 RL 기반 최적화 기법들과 여러 고해상도 벤치마크에서 비교 실험을 진행했습니다.
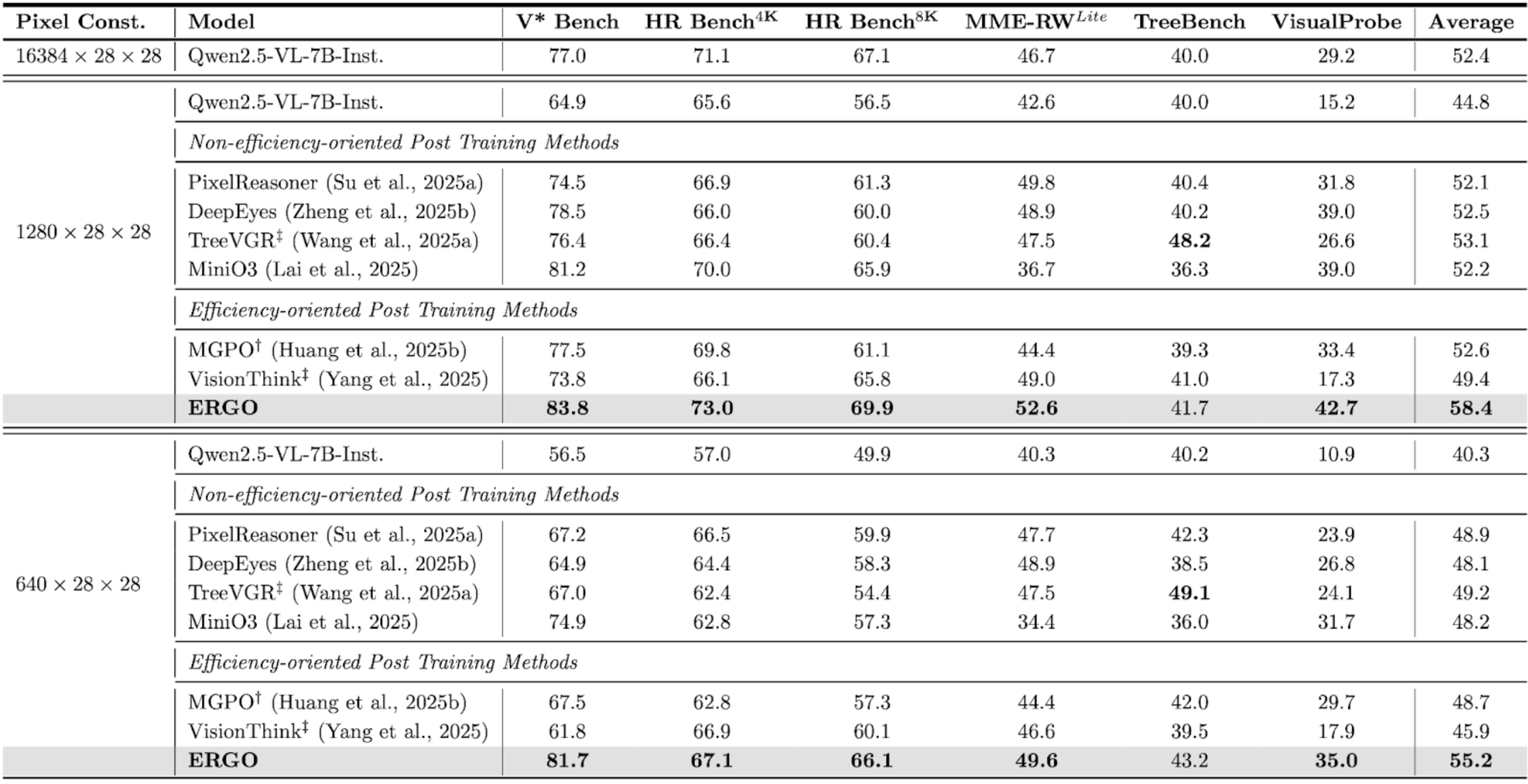
벤치마크 성능
동일한 입력 해상도(픽셀) 제약 조건에서, ERGO는 원본 모델과 기존 post-training 기법 대비 뚜렷한 성능 우위를 보였습니다.
비교 가능한 시각 정보 예산(visual input budget) 환경에서도 ERGO는 더 높은 벤치마크 점수를 기록했습니다. 이는 더 많은 시각 정보를 처리했기 때문이 아니라, 시각 연산을 더 효과적으로 활용했기 때문입니다. †는 저자 코드 기반 재현 결과, ‡는 각 방법의 원래 추론 파이프라인 사용 결과를 의미합니다.
효율성 평가
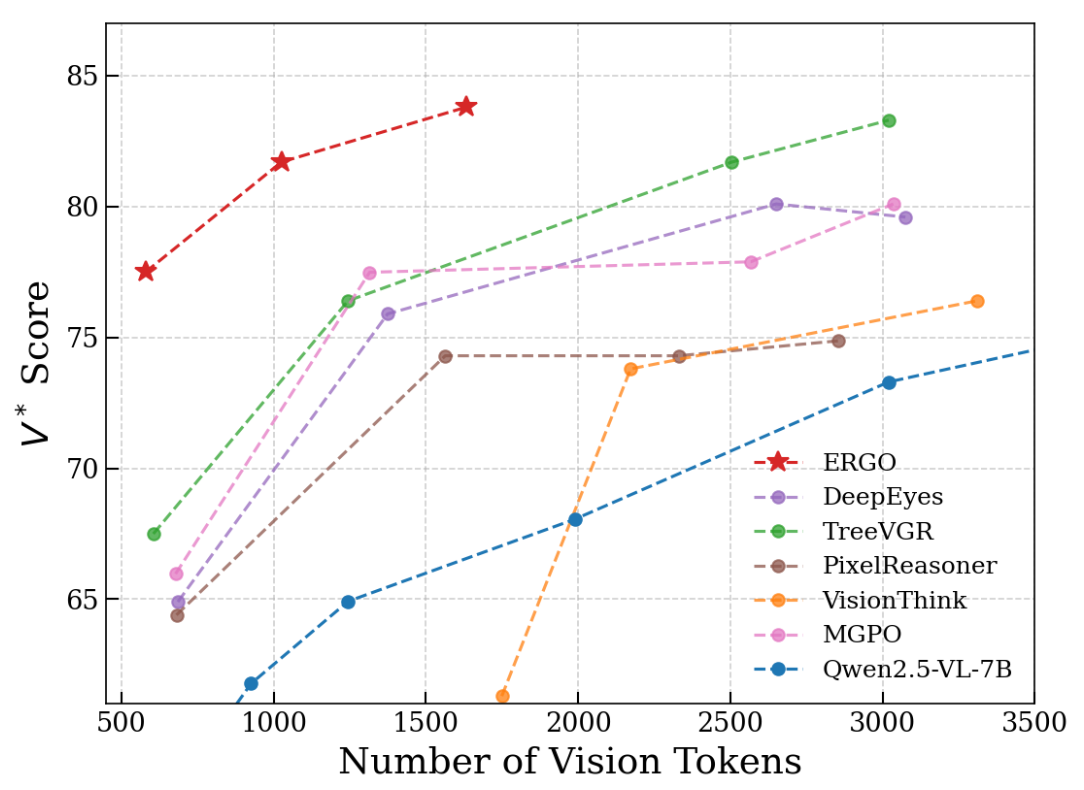
ERGO는 고해상도 시각 추론에서 효율성과 성능의 균형을 효과적으로 개선합니다.
기존 방법들은 비전 토큰 수를 늘려 정확도를 확보하는 경향이 있지만, ERGO는 훨씬 적은 토큰으로도 더 강력한 추론 성능을 달성합니다.
즉, 이미지를 전체적으로 처리하는 대신 텍스트 질의와 관련된 영역만 선택적으로 고화질화함으로써, 더 적은 수의 토큰으로 더 높은 정확도를 달성합니다.
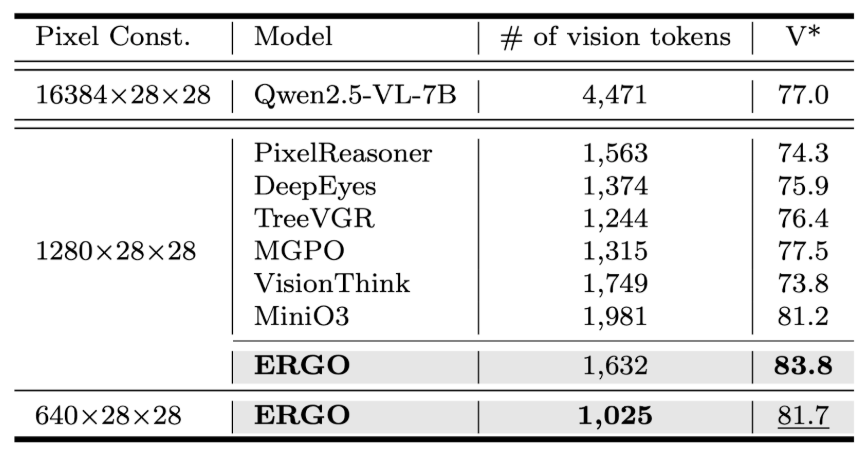

표 1과 2에서도 이러한 이점이 확인됩니다.
1,632 tokens → V* 83.8
1,025 tokens → V* 81.7
동시에 비교 방법 중 가장 빠른 실행 속도를 기록했습니다.
이는 ERGO가 토큰의 효율성뿐 아니라 실제 배포 환경에서의 실용적 효율성까지 개선했음을 보여줍니다.
소거 연구(Ablation Study)
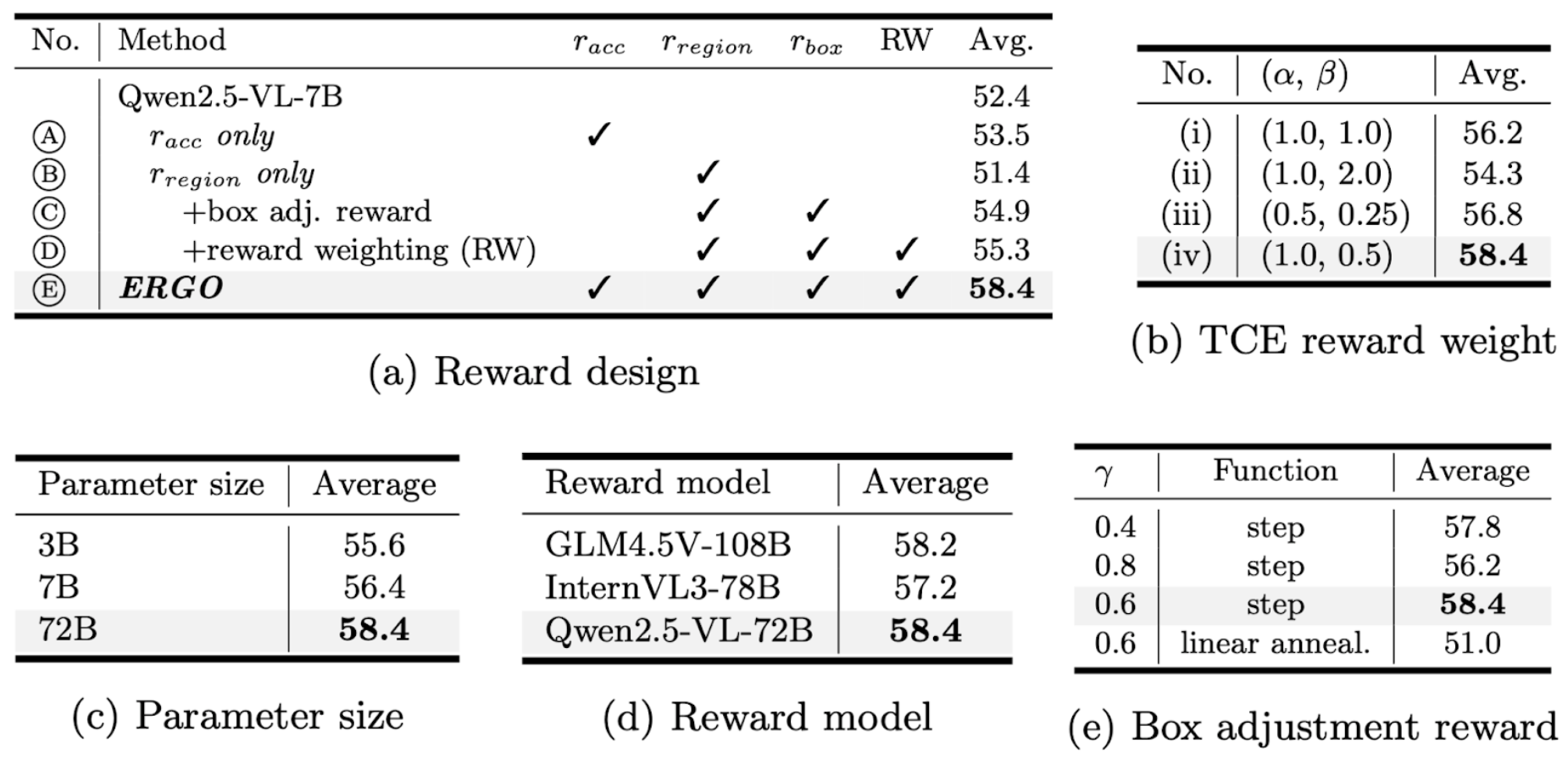
효율성 향상의 원인을 분석하기 위해 소거연구를 수행했습니다.
각 보상 요소를 추가할수록 성능이 일관되게 향상되었으며, 이는 단순한 정확도 개선만으로는 충분하지 않고 효율적인 영역 선택 학습이 필수적임을 보여줍니다.
특히 영역 보상(region reward)과 영역 크기 조정 보상(box-adjustment reward)이 불필요한 시각 연산을 줄이면서 과제 관련 영역에 집중하도록 하는 데 핵심적인 역할을 했습니다.
추가적인 보상 가중치, 파라미터 규모, 보상 모델 실험을 통해, 성능 향상이 모델의 구조적 변경만이 아닌 균형 잡힌 보상 설계의 결과임을 확인했습니다.
결론
ERGO는 LVLM의 고해상도 시각 이해 효율성을 크게 향상시킨 프레임워크입니다. 인지 주도적(perception-driven) 접근에서 추론 주도적(reasoning-driven perception) 방식으로 전환함으로써, 다운샘플링 한계를 문맥 기반 추론으로 극복할 수 있음을 보여주었습니다. 벤치마크 결과는 ERGO가 최대 3배까지 연산 오버헤드를 줄이면서도 더 높은 정확도를 달성함을 입증했습니다. 이번 연구는 고해상도 디테일과 빠른 추론 속도가 동시에 요구되는 복잡한 비전-언어 과제에 대해, 확장 가능하고 실제 배포에 적합한 실용적 솔루션을 제시한다는 점에서 의의가 있습니다.
📧 이 연구에 대해 추가로 궁금한 사항이 있으시면 아래 이메일 주소로 언제든지 문의해 주세요: contact@nota.ai.