[넷츠프레소 딥다이브] 양자화부터 그래프 최적화까지, 단계별 모델 배포 파이프라인

Jaehoon Lee
Technical Content Manager, Nota AI
시리즈 안내: 넷츠프레소 기술 블로그 2편
지난 1편에서는 Llama 3.2 1B를 엣지 디바이스에 배포하는 시나리오로 넷츠프레소의 워크플로우를 다뤘습니다. np workspace init부터 np run까지 네 줄의 CLI로 최적화 파이프라인을 구성하고, sweep으로 여러 설정을 자동 탐색하며, Probe로 최적화 전후 결과를 비교하는 흐름이었습니다.
이번 2편에서는 그 np run이 내부적으로 거치는 세 단계, --steps aq, go, gq의 안쪽으로 들어갑니다. 1편을 읽지 않으셨더라도 따라오실 수 있도록 필요한 맥락은 단계마다 함께 풀어드릴 예정이니 편하게 읽으셔도 좋습니다. 1편이 궁금하시다면 여기에서 보실 수 있습니다.
타깃 디바이스 배포의 세 가지 병목
PyTorch가 정의하는 연산자는 해마다 꾸준히 늘고 있습니다. 모델이 표현할 수 있는 연산의 폭도 함께 넓어졌습니다. 그러나 타깃 디바이스의 하드웨어 SDK가 이를 지원하는 속도는 그에 미치지 못합니다. 모델 학습은 끝났는데, 정작 칩 위에서는 필요한 연산자를 실행하지 못하는 일이 빈번합니다.
어떻게든 모델을 올렸다 해도 안심할 수 없습니다. 제한된 메모리와 연산력에 맞추려면 모델을 가볍게 깎아내야 합니다. 최근 AWQ 같은 기술 덕분에 가중치를 INT4로 줄이는 것 자체는 한결 쉬워졌습니다. 문제는 이 알고리즘을 내 모델과 디바이스에 맞춰 정확도 손실 없이 적용하기가 까다롭다는 점입니다.
가장 큰 문제는 이 모든 과정이 단절되어 있다는 점입니다. 자체 소프트웨어 스택이 완비된 일부 대형 벤더 환경을 제외하면, 여전히 수많은 임베디드 기기와 칩셋 환경에서 양자화, 그래프 최적화, 컴파일 도구가 파편화되어 있습니다. 단계가 넘어갈 때마다 입출력 포맷을 일일이 변환해야 하고, 디바이스가 바뀌면 이 전체 파이프라인을 처음부터 다시 검토해야 합니다.
넷츠프레소의 3단계 최적화 엔진(AQ, GO, GQ)은 이렇게 파편화된 병목을 단 하나의 파이프라인 안에서 해결하도록 개발했습니다.
Advanced Quantizer (AQ): 일곱 가지 양자화 알고리즘, 하나의 파이프라인모델 등록부터 바이너리 추출까지, 한 곳에서
개별 라이브러리로는 풀기 어려운 네 가지 장벽
AQ는 PyTorch 레벨 양자화의 표준으로 자리 잡은 7가지 핵심 알고리즘을 파이프라인의 첫 단계에서 제공합니다. 초경량 가중치 압축 기법 (AWQ, GPTQ, AutoRound, HQQ)부터 활성값(activation) 이상치를 다루는 기법(QuaRot, SmoothQuant), 그리고 동작 확인용 기본 반올림(RTN)을 모두 포함합니다. 나아가 새롭게 주목받는 양자화 기법들을 파이프라인에 지속적으로 통합하며 지원 풀(Pool)을 빠르게 확장해나가고 있습니다.
물론 이들 알고리즘은 오픈소스 라이브러리나 논문 코드로 직접 사용할 수도 있습니다. 그러나 한 모델에 여러 알고리즘을 적용해 비교하기란 매우 번거롭습니다. 최적화 결과를 다음 단계로 매끄럽게 넘기는 작업도 까다롭습니다. 알고리즘의 원리를 아는 것과 별개로, 실무에서는 다음과 같은 4가지 장벽을 직접 해결해야 합니다.
라이브러리 간 환경 충돌: AWQ, GPTQ, AutoRound, HQQ 등 주요 알고리즘은 각기 다른 패키지에 흩어져 있습니다. 요구하는 torch나 CUDA 버전도 서로 다릅니다. 단일 환경에서 여러 알고리즘을 테스트하는 일 자체가 큰 장벽입니다.
연구용 코드 수준의 한계: 최신 양자화 오픈소스는 대부분 특정 아키텍처나 데이터 타입에 종속되어 구현됩니다. 타깃이나 데이터셋 조건을 바꿔가며 교차 실험하기가 까다로워, 알고리즘 간 일관된 성능 비교를 만들기 매우 어렵습니다.
파편화된 데이터 전처리 규격: 라이브러리마다 요구하는 데이터 형태(Shape)와 시퀀스 길이가 제각각입니다. 동일한 데이터를 사용하더라도 알고리즘 개수만큼 전처리 작업을 반복해야 합니다.
단절된 출력 포맷: 대부분의 알고리즘이 지원하는 출력 포맷은 한정적입니다. 따라서 얻어낸 양자화 결과를 타깃 기기 컴파일 등 다음 단계로 넘기려면 프레임워크별 변환 어댑터를 별도로 확보해야 합니다.
AQ는 이 복잡한 의존성과 규격을 단 하나의 YAML 설정으로 통합합니다. 캘리브레이션(calibration) 데이터는 허깅페이스 허브(HuggingFace Hub)에서 자동으로 불러옵니다. 따라서 라이브러리마다 전처리 코드를 반복해 작성할 필요가 없습니다. 또한, 1편에서 다룬 sweep 기능을 활용하면 모든 알고리즘을 같은 평가 지표로 한 번에 비교할 수 있습니다. 결과적으로 AQ의 가치는 알고리즘의 단순 나열이 아니라, 파편화된 기술을 하나의 파이프라인 안에서 손쉽게 쓰도록 만들었다는 데 있습니다.
AQ가 파이프라인의 첫 단계인 이유
AWQ·GPTQ 같은 알고리즘은 PyTorch 가중치 원본에 직접 개입합니다. 이후 그래프 표현으로 변환되고 나면, 모델의 핵심인 민감한 가중치를 안전하게 보호할 수 없게 됩니다. 이 타이밍을 놓치면 후속 단계에서 문제가 생깁니다. 이후 모델의 연산 구조를 바꾸거나 데이터 정밀도를 본격적으로 낮추는 과정에서 정확도가 크게 흔들립니다. 결국 양자화 설정을 처음부터 다시 잡아야 합니다.

표 1: 넷츠프레소 최적화 파이프라인에서 AQ의 위치 (PyTorch 레벨, 그래프 변환 전 동작)
넷츠프레소가 AQ를 첫 단계로 배치한 이유는 또 있습니다. 파편화된 양자화 결과물을 넷츠프레소의 공통 중간 표현(NPIR)으로 자동 정규화하기 위해서입니다. AQ를 거친 모델은 GO, GQ, 컴파일, 프로파일링 단계까지 단절 없이 나아갑니다. 중간에 양자화 알고리즘을 바꾸더라도 이후 파이프라인을 다시 짤 필요가 없습니다.
NPIR과 Graph Optimizer (GO): 디바이스별 그래프 최적화
NPIR: 최적화 전용 공통 중간 표현
AQ 처리를 마친 PyTorch 모델은 다음 단계를 위해 새로운 형태의 그래프로 바뀝니다. 바로 넷츠프레소의 독자적인 중간 표현인 NPIR (NetsPresso Intermediate Representation)입니다. 이후 이어지는 GO와 GQ 작업은 모두 이 NPIR을 바탕으로 진행합니다.
그렇다면 NPIR은 구체적으로 어떤 구조이길래 GO와 GQ 작업을 단절 없이 이어갈 수 있을까요? 그 특징을 먼저 살펴본 뒤, 이어서 GO가 기기마다 모델을 어떻게 다르게 재조립하는지 알아보겠습니다.
ONNX vs NPIR: 범용 교환 포맷과 최적화 전용 표현의 차이
모델을 변환할 때 중간 표현이 필요하다면, ONNX를 사용하는 것이 일반적입니다. 주요 딥러닝 프레임워크(PyTorch, TensorFlow)와 추론 엔진(TensorRT, OpenVINO)이 대부분 이를 지원하기 때문입니다. “일단 ONNX로 변환하면 어디서든 돌릴 수 있다"는 범용성이 채택의 가장 큰 이유입니다.
그럼에도 넷츠프레소가 독자적인 NPIR을 구축한 이유는 명확합니다. 첫째는 표현의 한계를 극복하기 위함이며, 둘째는 파편화된 기기에 딱 맞는 최적화와 압축을 한 흐름으로 구현하기 위해서입니다.
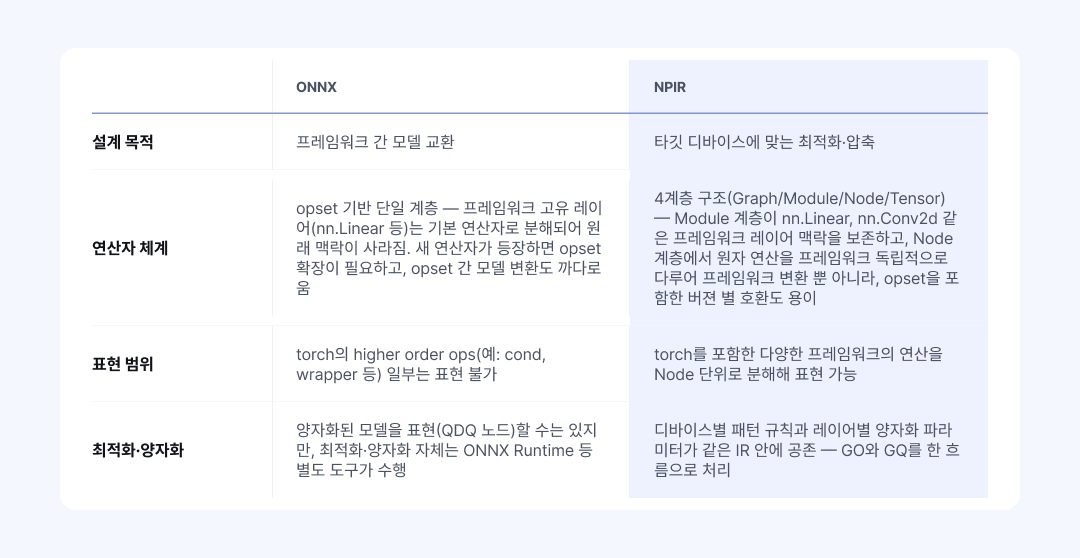
표 2: ONNX와 NPIR의 설계 목적·연산자 체계·표현 범위·최적화 방식 비교
이러한 구조적 차이는 실무에서 바로 드러납니다. ONNX 기반 워크플로우에서는 프레임워크 고유의 레이어 정보가 사라집니다. 예를 들어 PyTorch의 nn.Linear는 ONNX 변환 시 MatMul 연산(편향이 있으면 Add 포함)으로 분해됩니다. 가중치와 편향이 서로 다른 원자 연산자로 흩어지면서, 원래 하나의 선형 변환 레이어였다는 사실이 사라지는 것입니다.
이 정보의 소실은 레이어 단위의 판단이 필요한 시점에 문제로 드러납니다. 이 Linear 전체에 어떤 양자화 스킴을 적용할지, Conv + BatchNorm 같은 특정 레이어 조합을 한 단위로 묶어 변환할지 같은 판단은 "원래 이게 무슨 레이어였는지"를 알아야 가능합니다. 쪼개진 연산자들이 원래 한 덩어리였다는 사실을 잃어버리면, 결국 그래프 변환·최적화·양자화를 서로 다른 도구로 이어 붙여야 합니다.
그러나 넷츠프레소의 NPIR은 다릅니다. 원본 레이어의 맥락을 모듈(Module) 계층에 그대로 보존하면서, 가장 작은 단위의 원자 연산(Node)을 개별적으로 다룹니다. 덕분에 앞선 최적화 단계에서 묶어낸 연산 패턴이 다음 양자화 단계의 계산 단위로 단절 없이 이어집니다. 또한 복잡한 연산자를 Node 단위로 쪼개 관리하기 때문에, ONNX에서 opset이 달라질 때마다 겪게 되는 변환 호환성 문제에서도 상대적으로 자유롭습니다. 타깃 기기가 바뀌더라도 파이프라인을 처음부터 다시 엮을 필요가 없습니다.
Graph Optimizer: 150개+ 패턴 기반 디바이스 맞춤 최적화
양자화로 모델 크기를 줄였다고 해서 타깃 기기에서 무조건 빠르게 돌아가는 것은 아닙니다. 현업에서는 이 단계에서 크게 세 가지 장벽에 부딪힙니다.
미지원 연산자로 인한 실행 불가: 디바이스 SDK가 특정 연산자를 지원하지 않아 해당 연산자가 NPU에서 실행되지 못하는 경우 (예: LayerNorm이 Ethos-U NPU에서 거부되는 사례)
비효율적 연산 경로로 인한 성능 저하: 연산 자체는 지원하지만, 실행 속도가 현저히 느린 경로로 빠지는 경우입니다. (예: Einsum을 지원하지만, MatMul로 변환했을 때 속도가 몇 배 더 빨라지는 상황)
하드웨어 및 백엔드마다 다른 최적화 정답(파편화): 위의 두 문제에 대한 해결책이 디바이스 및 백엔드마다 전부 다릅니다. 예를 들어 XNNPACK 에서 그대로 둬야 할 연산자를 Ethos-U에서는 쪼개야 하고 그 반대도 성립하여, 한 곳에서 검증한 규칙을 다른 곳에 그대로 쓸 수 없습니다.
넷츠프레소의 GO는 수식적 동등성을 유지하는 그래프 변환 기법으로 비효율적인 연산을 먼저 걷어냅니다. 실제로 어떤 변환이 일어나는지 살펴보겠습니다.

표 3: GO의 동작 방식 예시, Ethos-U85에서 LayerNorm을 NPU 지원 연산자 조합으로 분해
위 예시에서 GO는 Ethos-U85가 소화하지 못하는 LayerNorm을 NPU 지원 연산자만으로 다시 내려 컴파일 실패를 해소합니다. 반대로 LayerNorm용 전용 커널이 있는 백엔드의 경우 LayerNorm을 분해하면 오히려 느려지기 때문에 LayerNorm을 원형 그대로 유지합니다.
이처럼 GO는 타깃 맞춤형 패턴 매칭을 통해, 같은 모델이라도 기기 특성에 맞춰 완전히 다른 구조의 그래프를 그려냅니다. 넷츠프레소는 150개 이상의 최적화 패턴 풀(Pool)을 갖추고 있으며, 타깃이 NPU인지 CPU인지에 따라 가장 유리한 규칙만 동적으로 골라냅니다. 그렇다면 이 수많은 규칙은 대체 어디서 온 걸까요?
이 규칙들은 단순한 이론적 최적화가 아닙니다. 노타가 수많은 상용 프로젝트를 수행하며 초소형 칩(Arm Cortex-M)부터 NPU, 서버용 LPU까지 다양한 하드웨어 환경에서 직접 부딪히고 해결하며 쌓아 올린 실전에서 축적한 데이터입니다.
지원하지 않는 연산자를 쪼개고, 느린 연산자를 빠른 것으로 교체하며, 양자화 블록의 경계를 설정하는 일부터 기기가 바뀔 때마다 수행하는 전체 재검증까지. 이 단계에서 고려해야 할 변수는 끝이 없습니다. 개별 팀이 이 방대한 과정을 처음부터 검증하려면 막대한 비용과 시간이 들 수밖에 없습니다. 넷츠프레소 GO는 이 구간을 실전에서 검증된 패턴으로 해결합니다.
Graph Quantizer (GQ): 레이어별 혼합 정밀도(mixed precision) 자동 배정
Capability Map과 Fail-Fast: 스킴 검증부터 캘리브레이션까지
GO 엔진이 최적화한 그래프는 GQ 엔진으로 전달되어 최종 압축 단계에 진입합니다. AQ가 가중치 손상을 방어하는 과정이었다면, GQ는 부동소수점(FP32/16) 형태의 가중치와 활성값을 정수(INT8/INT4)로 변환하여 최종 모델 크기와 추론 속도를 확정하는 엔진입니다.
다만 이 변환은 그래프 전체에 동일한 방식으로 일괄 적용되지 않습니다. 디바이스마다 연산자별로 지원하는 데이터 타입이 다르기 때문에, GQ는 그래프를 탐색하며 각 연산자가 지원하는 커널에 맞춰 양자화 스킴을 적용합니다. 이 과정은 사용자가 선택한 양자화 스킴과 타깃 하드웨어가 실제로 지원하는 범위를 맞춰가는 단계입니다.
양자화 스킴(Quantization Scheme)은 타깃 하드웨어의 물리적 제약에 따라 결정되어야 합니다. 넷츠프레소는 주요 기기별 지원 스펙을 '기능 맵(Capability Map)'으로 내장하여 이 과정을 시스템적으로 통제합니다.
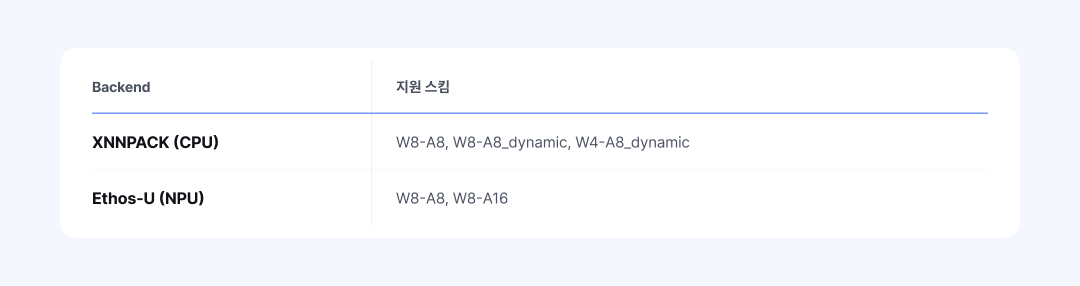
표 4: 백엔드별 지원 양자화 스킴
위 표와 같이 CPU(XNNPACK)는 실시간 스케일 계산이 필요한 동적 양자화(Dynamic)를 지원하지만, 특정 NPU(Ethos-U)는 정적 양자화(Static) 스킴만 허용합니다. 만약 기기 제약을 벗어난 스킴(예: Ethos-U에 W4-A8_dynamic)을 설정할 경우, 양자화가 시작되기 전 사전 검증기(Validator)가 Fail-Fast 메커니즘을 작동시킵니다. 이를 통해 엔지니어는 잘못된 설정으로 인한 컴파일 실패와 불필요한 런타임 대기 시간을 방지할 수 있습니다.
스킴 검증을 무사히 마치면 캘리브레이션(calibration)을 시작합니다. GQ는 사용자가 실제 서비스 환경에서 쓰려는 데이터를 모델에 직접 주입해 레이어별 활성값 범위를 측정합니다(Scale 및 Zero-point 계산). 여기에 더해 MinMax, percentile, histogram과 같이 데이터 분포에 맞는 다양한 캘리브레이션 기법을 제공해, 이상치(outlier)가 있는 모델에서도 정확도 하락을 최소화합니다.
Automatic Mixed Precision (AMP): 레이어별 양자화 민감도 자동 탐색
모든 레이어에 같은 비트를 적용하는 균일 양자화는 간단합니다. 하지만 항상 최선은 아닙니다. 레이어마다 양자화에 반응하는 민감도가 다르기 때문입니다. Llama 3.2 1B 모델처럼 양자화 모듈이 100여 개에 달하면, 이를 조합하는 경우의 수는 약 2의 100승개로 늘어납니다. 사실상 사람이 하나씩 전수 탐색하는 것은 불가능합니다.
넷츠프레소의 AMP는 자동 탐색 알고리즘으로 이 문제를 해결합니다. 레이어별 양자화 민감도를 측정한 뒤, 민감한 모듈에는 높은 정밀도를, 나머지에는 낮은 정밀도를 자동으로 배정합니다. 예를 들어 아래 표의 경우 민감한 레이어에 FP32를, 나머지에 INT8을 적용한 결과입니다.
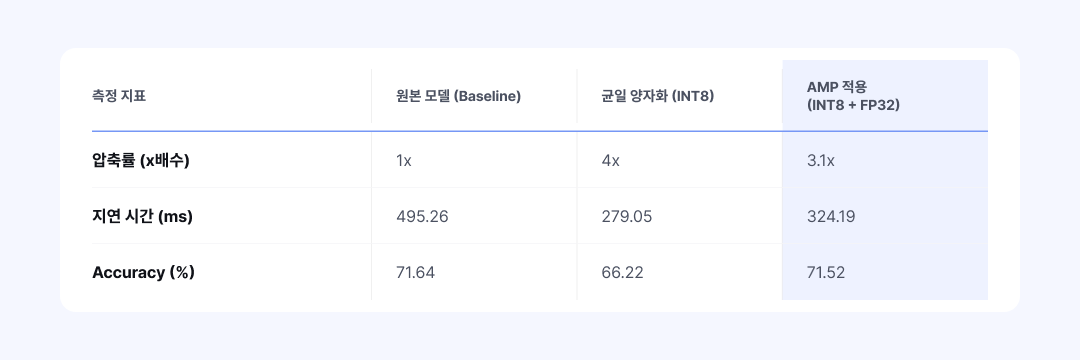
표 5: vit_b_16 모델 기준 원본·균일 양자화(INT8)·AMP (INT8+FP32) 성능 비교
균일 양자화를 적용해 모델 정확도가 떨어졌을 때 AMP의 진가가 드러납니다. 전체 모델의 평균 크기는 작게 유지하면서, 민감한 레이어에만 정밀도를 높여 정확도 손실을 억제합니다. 엔지니어가 수백 개의 조합을 일일이 테스트해야 했던 고통스러운 작업을 단 한 번의 실행으로 단축해 줍니다.
AMP가 찾아낸 결과를 더 다듬고 싶다면 어떻게 해야 할까요? 수동 모드(Manual Mixed Precision)로 특정 레이어만 직접 조율할 수 있습니다. AMP의 자동 배정 결과를 기준점 삼아 필요한 부분만 빠르게 손보는 실용적인 워크플로우입니다. 세부적인 후보 정밀도나 탐색 비율을 제어하고 싶다면 설정 파일(run.detail.yaml)에서 직접 지정할 수도 있습니다.
Compiler와 Profiler: 크로스 컴파일에서 온디바이스 벤치마크까지
AQ → GO → GQ를 거쳐 최적화한 NPIR 그래프를 이제 실제 기기가 읽을 수 있는 바이너리 코드로 변환할 차례입니다.
컴파일러(Compiler) 모듈은 이 최적화 그래프를 바탕으로 타깃 환경에 맞는 바이너리(예: ExecuTorch 기반 .pte)를 생성합니다. CPU(M4)든 NPU(Ethos-U85)든 엔지니어가 까다로운 크로스 컴파일(Cross Compile) 환경을 직접 맞출 필요가 없습니다. 프로젝트 설정에 따라 최적의 변환 경로를 자동으로 결정합니다.
변환을 마친 바이너리는 곧바로 타깃 보드로 넘어가 프로파일러(Profiler)와 만납니다. 프로파일러는 기기에서 발생하는 지연 시간(Latency)과 메모리 사용량을 직접 측정합니다. 그 결과를 np report 명령어를 통해 깔끔한 표 형태로 보여줍니다. 원본 모델이 세 단계를 거치며 얼마나 가벼워졌는지 눈으로 직접 확인할 수 있습니다.
당장 연결할 타깃 보드가 없더라도 괜찮습니다. 설정 파일(run.yaml)에서 프로파일링 항목을 비워두고 최적화 파이프라인만 먼저 실행해 볼 수 있습니다.
결과적으로 컴파일러와 프로파일러는 최적화 모델을 타깃 기기가 즉시 실행할 수 있게 돕고, 그 성능을 교차 검증합니다. 넷츠프레소 파이프라인의 시작과 끝(End-to-End)을 완성하는 마지막 단계입니다.
최적화 벤치마크: Llama 3.2 1B 실측 결과
Llama 3.2 1B 양자화 벤치마크: AQ + GO + GQ 풀 파이프라인
1편에서 np report로 확인했던 최종 결과를 다시 한번 살펴보겠습니다. 이번에는 최적화 파이프라인(AQ, GO, GQ)의 각 단계가 모델을 구체적으로 어떻게 바꾸어 놓는지 기술적인 관점에서 분석합니다.
[1단계] AQ: 메모리 87% 절감
가중치를 4비트(INT4)로 줄인 직접적인 성과입니다. 단, 이때 지연 시간(Latency)은 변하지 않습니다. AQ는 가중치의 저장 방식만 1차로 바꿔둘 뿐, 연산을 수행하는 실행 그래프 자체는 아직 건드리지 않았기 때문입니다.
[2단계] GO: 지연 시간 17% 단축
Noop Reshape 제거, SiLU 접기, MatmulToConv 교체 등 넷츠프레소의 핵심 패턴 변환 기술이 누적된 결과입니다. 이 과정에서 언어 모델의 품질(PPL, Perplexity)은 전혀 떨어지지 않습니다. 결괏값이 완벽히 일치하는 안전한 수학적 변환만 수행하기 때문입니다.
[3단계] GQ: 지연 시간 추가 60% 단축
무거운 부동소수점 연산을 가벼운 정수 연산으로 바꾼 결과입니다. 마침내 기기가 최고 속도로 동작하기 시작합니다. PPL 수치는 31.19에서 31.30으로 아주 살짝 오릅니다. 정수 변환 시 필연적으로 발생하는 오차지만, 앞선 AQ 단계에서 핵심 가중치를 미리 보호해 둔 덕분에 원본 모델(27.63) 대비 충분히 허용 가능한 범위 안에 머뭅니다.
※ 아래 수치는 설명을 위한 예시이며, 결과는 모델·하드웨어·설정 조합에 따라 달라질 수 있습니다.
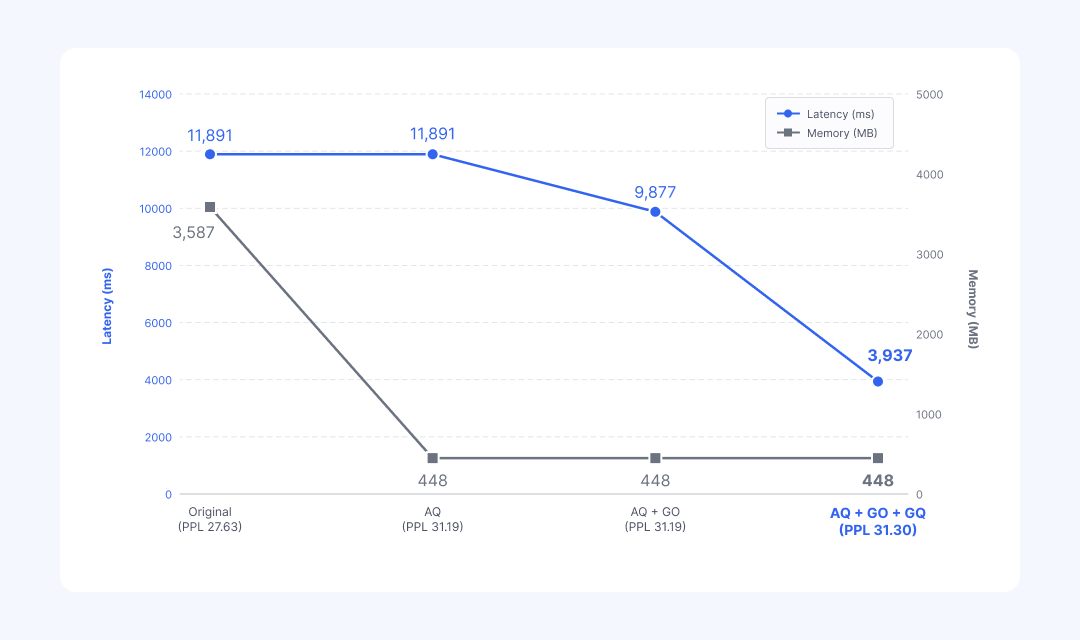
표 6: Llama 3.2 1B 모델의 AQ → GO → GQ 단계별 지연 시간·메모리·PPL 변화
최종 결과: 지연 시간 67% 단축, 메모리 87% 절감 (PPL 27.63 → 31.30) YAML 한 벌과 np run 명령어 한 번으로 만들어 낸 성과입니다.
이 파이프라인은 30B 이상의 거대 모델에서도 흔들림 없이 작동합니다. 실제로 노타가 진행한 서버용 LPU 배포 프로젝트에서는 MXFP4, AWQ, 그리고 혼합 정밀도(Mixed Precision) 기법을 조합하여 원본 모델 크기를 약 3분의 1로 압축했습니다. 그러면서도 정확도 저하를 1% 이내로 유지했습니다.
💡 [NPU & 비전 모델에서도 파이프라인은 동일합니다]
앞선 사례가 CPU 환경이었다면, 완전히 다른 초저전력 NPU(Arm Ethos-U)에서는 어떨까요? 음성 인식(Conformer)이나 비전 모델(ResNet50 등)을 타깃으로 설정해도 파이프라인은 수정 없이 동일하게 작동합니다. 타깃이 바뀌면 GO 엔진이 그래프를 새로 구성하기 때문입니다. 실제로 비전 모델의 경우 AQ 단계 없이 GO와 GQ만 거쳐도 최대 42배의 속도 향상을 기록하며 그 확장성을 증명하고 있습니다.
넷츠프레소 없이 직접 구성한다면: 6단계 파이프라인의 현실
지금까지 살펴본 AQ, GO, GQ 파이프라인을 넷츠프레소 없이 직접 구축한다고 가정해 보겠습니다. 최소 6개의 파편화된 단계를 거쳐야 하며, 각 단계마다 수많은 시행착오를 감수해야 합니다.
PyTorch 양자화: autoawq 등 라이브러리 간 환경 충돌, 모델별 토크나이저 세팅, 코퍼스 전처리.
그래프 변환: torch.onnx.export의 잦은 실패, 동적 shape 및 커스텀 연산자 처리 한계.
그래프 최적화: NPU에서는 쪼개고 CPU에서는 묶어야 하는 규칙을 타깃마다 수작업으로 검증.
하드웨어 양자화: TensorRT, OpenVINO, Vela 등 런타임마다 완전히 다른 툴체인과 포맷 요구.
크로스 컴파일: 임베디드 타깃의 경우 크로스 컴파일 환경을 맞추는 것 자체가 별도 작업.
프로파일링: 디바이스 워밍업, 지연 시간·메모리 측정 스크립트 작성 및 오차 디버깅 역추적.
가장 큰 문제는 각 단계의 입출력 포맷이 전부 다르다는 점입니다. 이 툴체인들을 억지로 이어 붙이는 것 자체가 엄청난 수고를 동반합니다. 게다가 타깃 기기가 단 하나라도 바뀌면, 3~6번 과정은 사실상 처음부터 다시 세팅해야 합니다.

표 7: 넷츠프레소 AQ·GO·GQ 엔진이 6단계 수동 파이프라인을 대체하는 핵심 역할 요약
어떤 모델, 어떤 기기를 선택하든 엔지니어가 해야 할 일은 단 하나입니다. 설정 파일(YAML) 한 벌을 작성하고 np run 명령어를 한 번 입력하는 것. 그것만으로 이 모든 최적화 여정이 넷츠프레소 위에서 자동으로 완료됩니다.
이 파이프라인의 기반에는 노타가 수년간 현장에서 직접 부딪히며 쌓아 올린 방대한 하드웨어 배포 경험이 자리하고 있습니다.
초소형 Arm Cortex-M부터 NVIDIA Jetson, Intel Xeon, AWS Inferentia는 물론 Hailo-8, FURIOSA RNGD 같은 최신 NPU에 이르기까지. 다양한 칩셋 환경에 100종 이상의 AI 모델을 배포하며 축적한 '진짜 실전 데이터(패턴 규칙, 양자화 노하우)'가 넷츠프레소 엔진의 뼈대입니다.
이 글에서 다룬 AQ, GO, GQ 파이프라인은 현재 넷츠프레소 CLI에서 사용할 수 있습니다. 직접 모델을 올려보고 싶으시다면 데모를 통해 확인해 보세요.

이 글에서 사용한 벤치마크 수치는 특정 모델·하드웨어·설정 조합에서의 결과이며, 실제 성능은 환경에 따라 달라질 수 있습니다.
이 연구에 대해 추가로 궁금한 사항이 있으시면 아래 이메일 주소로 언제든지 문의해 주세요: 📧 contact@nota.ai.
노타 AI의 최신 인사이트, 이제 LinkedIn에서도 만나보세요. 엣지 AI 트렌드부터 기술 업데이트까지 — Edge Insights 뉴스레터를 구독하고 가장 먼저 받아보세요. 👉 구독하기또한, AI 최적화 기술에 관심이 있으시면 저희 웹사이트 🔗 netspresso.ai.를 방문해 보세요.