[넷츠프레소 톺아보기] 모델 최적화부터 타깃 배포까지 한 번에 끝내는 플랫폼

Jaehoon Lee
Technical Content Manager, Nota AI
AI 모델 최적화, 왜 하드웨어에서 안 돌아갈까
칩은 완성됐는데, 모델이 올라가지 않습니다
AI 모델을 자사 칩에 올려본 경험이 있다면, 아래 상황이 낯설지 않을 겁니다.
고객사에서 연락이 옵니다. "우리 모델 올려봤는데, 안 돌아갑니다." 확인해 보면 특정 레이어의 연산자가 타깃 런타임에서 지원되지 않아 실행이 실패했습니다. 우회 경로를 찾아 겨우 포팅하면, 이번엔 추론 지연시간이 요구 스펙의 세 배입니다.
양자화를 걸면 정확도가 무너지고, 그래프를 최적화하면 다른 레이어에서 새로운 오류가 터집니다. 설상가상으로 어제 성공했던 설정값조차 새로운 모델에는 통하지 않으며, 단편적인 로그만으로는 문제의 레이어를 특정하기도 어렵습니다. 칩 설계가 끝났고 성능도 검증됐으며 샘플까지 나왔건만, 고객이 원하는 모델을 마주할 때면 늘 출발선으로 되돌아가고 맙니다.
모델마다 구조가 다르고, 요구하는 연산이 다르고, 최적화 경로가 다릅니다. 결국 모델 하나를 올릴 때마다 수작업 튜닝을 반복하게 됩니다. 칩의 성능이 아무리 좋아도, 모델이 올라가지 않으면 고객에게 증명할 방법이 없습니다.
이러한 간극이 생기는 이유는 칩 설계와 모델 최적화가 서로 다른 전문 영역이기 때문입니다. 타깃 디바이스가 다양해진 환경에서, 모델마다 다른 연산자 구성과 칩마다 다른 런타임 제약을 수작업으로 맞추는 데는 한계가 있습니다. 오늘 소개할 넷츠프레소(NetsPresso®)는 바로 이 문제를 풀기 위해 만들어졌습니다.
CLI로 최적화 파이프라인 구성하기
모델 등록부터 바이너리 추출까지, 한 곳에서
넷츠프레소는 학습된 AI 모델을 다양한 타깃 하드웨어에 배포 가능한 형태로 최적화하는 플랫폼으로, 특정 모델 프레임워크나 하드웨어에 종속되지 않도록 설계되었습니다. 모델 크기·추론 속도·정밀도를 동시에 다루고, 타깃 런타임용 바이너리 컴파일까지 하나의 파이프라인 안에서 끝납니다.

사진 1: 넷츠프레소의 모델 최적화 파이프라인. 원본 모델이 IR 변환, 그래프 최적화, 양자화, 프로파일링을 거쳐 배포 가능한 형태로 변환됩니다.
시나리오: Llama 3.2 1B를 엣지 디바이스에 배포하기
이해를 돕기 위해 하나의 시나리오를 설정해 보겠습니다.
상황: Llama 3.2 1B 모델을 엣지 디바이스에 배포해야 하는 상황.
목표: 추론 정확도를 유지하면서, 모델 크기와 지연시간을 줄이는 것.
시작은 간단합니다. 모델과 타깃 하드웨어를 지정하고, 최적화 파이프라인을 정의한 뒤 실행하면 됩니다.
$ np workspace init
# 프로젝트 생성: 모델, 데이터셋, 타깃 하드웨어 지정
$ np project create --model llama3.2_1b --calibration-dataset llama3.2_1b-calib --device raspberry_pi_5_16gb --runtime executorch --backend xnnpack
# 실험 생성: 최적화 파이프라인 정의
$ np experiment create --steps aq, go, gq
# 파이프라인 실행
$ np run
※ 이 예시는 넷츠프레소에 사전 등록된 프리셋 조합을 사용했습니다. 전체 지원 목록은 NP CLI에서 확인할 수 있습니다.
YAML 설정과 파이프라인 실행
np project create는 하나의 모델, 하나의 디바이스, 하나의 런타임 조합을 프로젝트로 고정합니다. 이 프로젝트 위에서 np experiment create를 실행하면 aq(Advanced Quantize, 모델 가중치 양자화), go(Graph Optimize, 연산 그래프 최적화), gq(Graph Quantize, 하드웨어 맞춤 양자화) 세 단계에 맞는 YAML 설정 파일이 생성되는데, 양자화 스킴, 프로파일 설정, 평가 기준이 이미 채워진 상태입니다. 기본 설정 그대로 실행할 수도 있고, 필요하면 YAML을 열어 세부 파라미터를 조정할 수도 있습니다. 아래는 자동 생성된 YAML의 일부입니다.
steps:
- advanced_quantize:
algorithm: AWQ # Available: RTN, AWQ, AUTOROUND, QUAROT, SMOOTHQUANT, GPTQ
scheme: W4-A8_dynamic # Available: W4-A8_dynamic, W8-A8, W8-A8_dynamic
- graph_optimize: null
- graph_quantize:
scheme: W4-A8_dynamic # Available: W4-A8_dynamic, W8-A8, W8-A8_dynamic
automatic_mixed_precision: null # Available: GREEDY
profile:
- INPUT_MODEL
- ADVANCED_QUANTIZE
- GRAPH_OPTIMIZE
- OUTPUT_MODEL
evaluate:
- model: INPUT_MODEL
metric:
- PPL
- model: ADVANCED_QUANTIZE
metric:
- PPL
- model: GRAPH_OPTIMIZE
metric:
- PPL
- model: OUTPUT_MODEL
metric:
- PPL
LLM 특화 설정(sequence length, KV cache, disaggregate)도 기본 포함되어 초기 세팅 부담을 줄여줍니다. 이 시나리오에서는 넷츠프레소에 사전 등록된 프리셋 모델을 사용했지만, 자체 학습한 커스텀 모델도 np model register로 등록한 뒤 동일한 흐름으로 진행할 수 있습니다.
np run을 실행하면 넷츠프레소는 모델을 자체 중간 표현인 NPIR(NetsPresso Intermediate Representation)로 변환한 뒤, YAML에 정의된 최적화 단계를 순서대로 수행합니다. 최적화가 끝나면 평가(evaluate)와 프로파일링(profile)까지 한 번에 이어집니다. 평가는 최적화 전후의 정확도를 비교하고, 프로파일링은 실제 타깃 하드웨어에서 지연시간과 메모리 사용량을 측정합니다. 이 과정이 하나의 파이프라인 안에서 연속으로 이어집니다.
결과 확인: np report와 np export
파이프라인 실행이 끝나면, 가장 먼저 할 일은 결과를 확인하는 것입니다. np report를 실행하면 최적화 결과가 한 테이블에 정리됩니다. 아래는 출력 예시입니다.
※ report 출력의 수치는 설명을 위한 예시이며, 결과는 모델·하드웨어·설정 조합에 따라 달라질 수 있습니다.
최종 단계(GQ) 기준으로 PPL 31.30, 지연시간 3936.81 ms(원본 대비 약 67% 감소), 메모리 448.42 MB(약 87% 감소)를 확인할 수 있습니다. PPL은 원본(27.63) 대비 소폭 상승했지만, 메모리와 지연시간은 대폭 줄었습니다. 원하는 수준이라면 np export로 타깃 하드웨어용 바이너리를 바로 추출할 수 있습니다. 모델과 타깃을 지정하고, YAML 하나 생성하고, np run 한 번 실행한 것이 전부입니다.
하나의 설정으로 결과를 얻었습니다. 그런데 이 결과가 최선일까요?
양자화 알고리즘 자동 비교
한 번에 안 끝나니까, 여러 설정을 한 번에 비교합니다
AWQ로 양자화한 결과를 확인했지만, GPTQ였다면 정확도가 달라질 수 있고, AMP(Automatic Mixed Precision) 적용 여부에 따라서도 결과가 크게 갈립니다. 최적의 조합을 찾으려면 여러 설정을 비교해야 하는데, 이 과정을 수동으로 반복하기에는 시간과 리소스 부담이 큽니다.
sweep: 후보군을 선언하고 자동으로 비교
매번 수동으로 비교하는 대신, YAML에 sweep: 블록을 추가하면 후보군을 한 번에 선언하고 시스템이 탐색하도록 맡길 수 있습니다. 예를 들어 AQ 단계에서 양자화 알고리즘을 AWQ와 GPTQ로 나눠 비교하고, GQ 단계에서 AMP 적용 여부를 조합하는 식입니다. sweep: 블록에 후보 조합을 나열하고 best: 기준(PPL, Latency 등)을 지정하면, 넷츠프레소가 각 조합을 자동으로 실행한 뒤 평가 지표에 따라 최적 결과를 선택합니다.
np report를 실행하면 variant별 결과가 한 테이블에 정리되어, 동일한 조건에서 알고리즘과 설정만 달라졌을 때 정확도·지연시간·메모리가 어떻게 변하는지 한눈에 비교할 수 있습니다. 정확도가 가장 높은 조합을 선택할 수도 있고, np report --sort latency처럼 정렬 기준을 바꿔 지연시간 우선으로 판단할 수도 있습니다. 자동 탐색의 목적은 맹목적인 자동화가 아니라, 근거 있는 의사결정을 돕는 것입니다.
그런데 이 결과가 왜 나은지, 어떤 레이어에서 차이가 생기는지까지 확인할 수 있다면 어떨까요?
모델 최적화 시각화 도구
어디서 달라졌는지, 눈으로 확인합니다
넷츠프레소에는 Probe라는 시각화 도구가 내장되어 있습니다. 자동 탐색이 끝난 뒤, 터미널에서 한 줄이면 바로 확인할 수 있습니다.
이 명령을 실행하면 시각화 링크가 생성되고, 이를 통해 Probe에 접근합니다. 최적화 전후의 모델 그래프가 나란히 표시되고, 어떤 연산이 융합되었는지, 어떤 레이어가 양자화되었는지를 시각적으로 확인할 수 있습니다.레이어별 SNR과 지연시간 분포도 확인할 수 있어, 자동 탐색이 골라낸 결과가 왜 나은지를 레이어 단위로 파악할 수 있습니다.
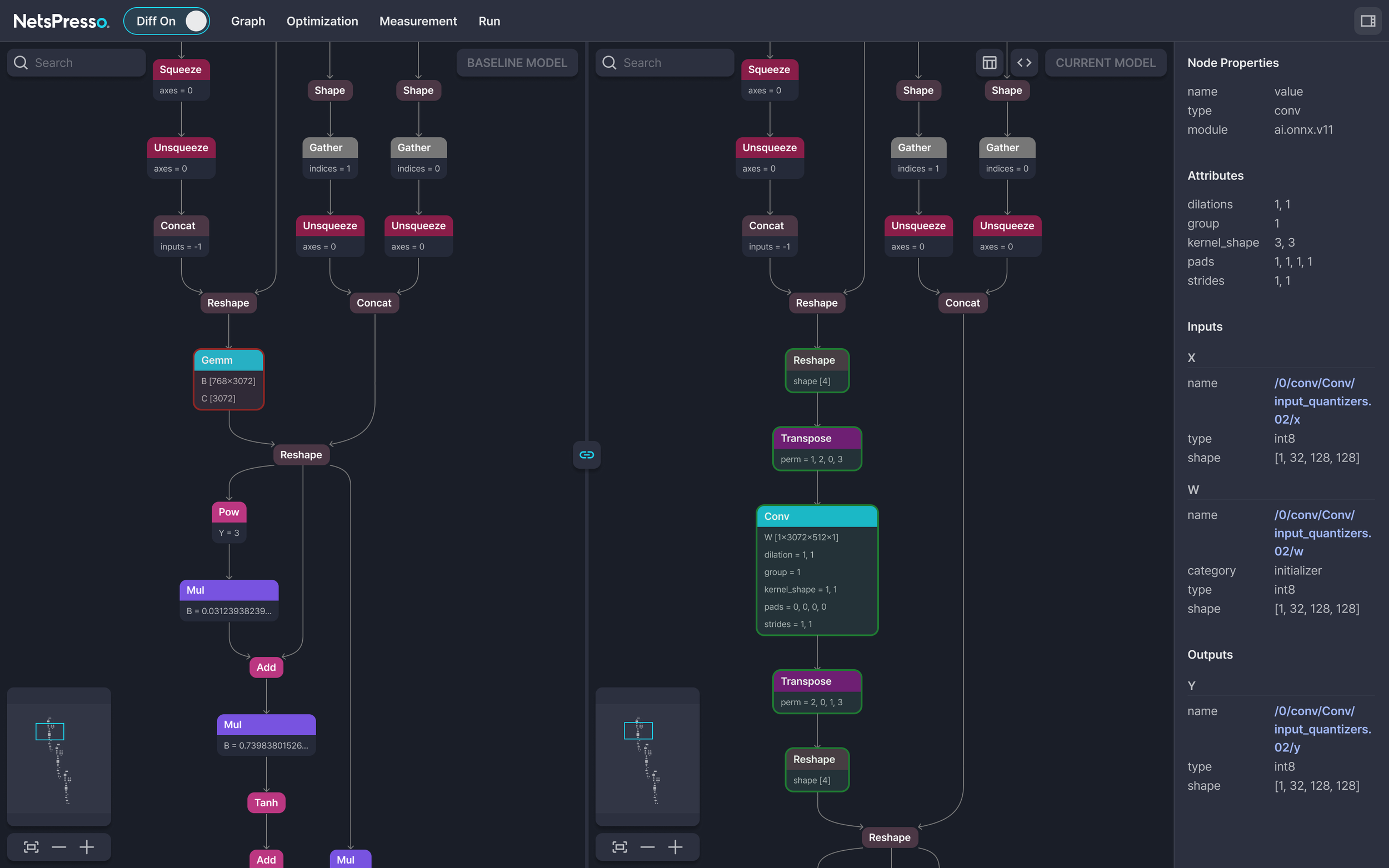
사진 2: Probe의 Diff 모드에서 본 최적화 전후 모델 그래프 비교. 노드별 속성과 양자화 적용 여부를 레이어 단위로 확인할 수 있습니다.
지금까지의 흐름을 돌아보면, 파이프라인 실행과 자동 탐색은 터미널에서, 결과 분석은 브라우저에서 이루어졌습니다. 넷츠프레소는 이 워크플로우를 Cross UI라고 부릅니다. CLI의 실행력과 GUI의 직관성을 하나의 플랫폼 안에서 연결하는 구조입니다. 별도 도구를 설치하거나 결과 파일을 옮길 필요 없이, 실행부터 시각적 검증까지 끊김 없이 이어집니다.
Coming next: Dashboard 다음 업데이트에서는 여러 실험 결과를 산점도로 비교하는 Dashboard가 추가됩니다. Probe 진단 → 설정 수정 → 재실험의 반복까지 구조적으로 지원할 예정입니다.
넷츠프레소 도입 환경과 호환성
기존 인프라, 그대로 쓸 수 있습니다
그렇다면 이제 궁금한 것은 실제로 우리 환경에 도입할 수 있을지입니다. 넷츠프레소는 다양한 인프라 환경에서 실행될 수 있도록 설계되었습니다.
GPU가 없어도 사용할 수 있습니다. GPU 환경이 아니더라도 CPU만으로 최적화 파이프라인을 실행할 수 있습니다. GPU가 있으면 --gpu-device 옵션으로 지정해서 활용할 수 있고, 멀티 GPU도 지원합니다.
Docker 이미지와 Python 라이브러리, 두 가지 방식으로 제공됩니다. Docker 이미지로 환경 구성 없이 바로 시작할 수 있고, pip install로 기존 Python 환경에서 설치할 수도 있습니다.
모델이 외부로 나가지 않습니다. On-Premise 환경에서도 사용할 수 있습니다. 모델과 데이터셋은 사용자의 로컬 경로에 그대로 남고, 넷츠프레소는 해당 경로를 참조만 합니다. workspace에 저장되는 것은 메타데이터(JSON 설정 파일)뿐입니다. 모델을 외부에 노출하고 싶지 않은 환경에서도 기존 보안 정책을 유지하면서 사용할 수 있습니다.
타깃 디바이스는 엣지부터 서버까지 커버합니다. 모바일/엣지 디바이스부터 서버 GPU까지, 주요 런타임과 하드웨어를 지원합니다.
모델 최적화부터 타깃 배포까지 하나의 흐름 안에서
이 글에서는 하나의 시나리오를 따라가며 넷츠프레소의 워크플로우를 살펴봤습니다. 네 줄의 CLI 명령으로 파이프라인을 구성하고, sweep으로 여러 설정을 자동으로 탐색하며, Probe로 최적화 전후를 시각적으로 검증하는 과정까지. 모델 배포에 필요한 작업이 하나의 플랫폼 안에서 매끄럽게 이어집니다.
이렇듯 넷츠프레소가 제공하는 진정한 가치는 이 모든 과정의 '통합'과 '효율화'에 있습니다. 양자화 스킴을 바꾸고, 흩어진 결과 파일을 모아 비교하고, 그래프를 뜯어보기 위해 여러 도구를 전전하며 수작업으로 채워야 했던 구간을 하나로 묶어냈습니다.
모델마다, 칩마다 수작업 튜닝을 반복해야 했던 배포 병목은 넷츠프레소가 해결하겠습니다. 자동화된 탐색과 직관적인 시각적 근거를 바탕으로, 어떤 환경에서든 가장 확실한 최적화 전략을 효율적으로 결정할 수 있습니다. 이제 '더 나은 모델'과 '더 나은 하드웨어'를 만드는 핵심 경쟁력에 온전히 집중해 보시기를 바랍니다.

다음 편에서는 이 파이프라인 안에서 무슨 일이 일어나는지를 다룹니다. NPIR, 세 단계 최적화 엔진(AQ, GO, GQ)의 구조를 열어보겠습니다.
이 연구에 대해 추가로 궁금한 사항이 있으시면 아래 이메일 주소로 언제든지 문의해 주세요: 📧 contact@nota.ai.
노타 AI의 최신 인사이트, 이제 LinkedIn에서도 만나보세요. 엣지 AI 트렌드부터 기술 업데이트까지 — Edge Insights 뉴스레터를 구독하고 가장 먼저 받아보세요. 👉 구독하기또한, AI 최적화 기술에 관심이 있으시면 저희 웹사이트 🔗 netspresso.ai.를 방문해 보세요.