LLaMA-3.2-Vision 경량화를 위한 크로스 어텐션 기반의 시각 정보 축소

Jewon Lee | Ki-Ung Song | Seungmin Yang | Donguk Lim | Jaeyeon Kim | Wooksu Shin | Bo-Kyeong Kim | Tae-Ho Kim
EdgeFM Team, Nota AI

Yong Jae Lee, Ph. D.
Associate Professor, UW-Madison
개요
Trimmed-Llama는 크로스 어텐션 기반 대규모 비전-언어 모델(LVLM)의 Key-Value(KV) 캐시 사용량과 추론 지연(latency)을 성능 저하 없이 줄입니다.
LVLM의 크로스 어텐션 맵에서 희소성(sparsity)을 확인하였으며, 대부분의 시각 특징이 초기 레이어에서 선택되고 이후 레이어에서는 큰 변화가 없는 일관된 계층별 패턴을 보인다는 것을 발견했습니다.
본 연구는 CVPR 2025 ELVM (Efficient Large Vision Language Model) 워크숍에서 채택되었습니다.
연구의 주요 메시지
시각 토큰 축소(Visual token reduction)는 불필요한 이미지 특징을 가지치기하여 대규모 비전-언어 모델(LVLMs)의 추론 비용을 효과적으로 절감할 수 있습니다. 기존 연구들은 주로 셀프 어텐션 기반 LVLM에 초점을 맞춘 반면, 본 연구는 더 우수한 성능을 보이는 크로스 어텐션 기반 모델을 대상으로 합니다. 크로스 어텐션 레이어에서 이미지 토큰의 Key-Value (KV) 캐시는 셀프 어텐션 레이어의 텍스트 토큰보다 현저히 커서 주요한 연산 병목으로 작용한다는 점이 관찰되었습니다.
이러한 문제를 해결하기 위해 제안된 Trimmed Llama는 크로스 어텐션 맵의 희소성(sparsity)을 활용하여 불필요한 시각 특징을 추가 학습 없이 가지치기합니다. 또한, 전체 시각 특징의 50%를 축소함으로써 기존 벤치마크 성능은 유지하면서 KV 캐시 요구량, 추론 지연(latency), 메모리 사용량을 모두 줄입니다.
연구의 의의 및 중요성
크로스 어텐션 레이어에서 이미지 토큰의 KV 캐시가 셀프 어텐션 레이어의 텍스트 토큰보다 현저히 큰 것으로 나타났으며, 이는 연산 병목의 주요 원인으로 작용합니다. 이러한 문제를 해결하기 위해, 크로스 어텐션의 희소성을 활용하여 불필요한 시각 특징을 선택적으로 가지치하는 방법을 제안합니다.
연구 방법론

어텐션 가중치 기반 기준을 활용해, 첫 번째 크로스 어텐션 블록에서 시각 특징을 가지치기합니다.
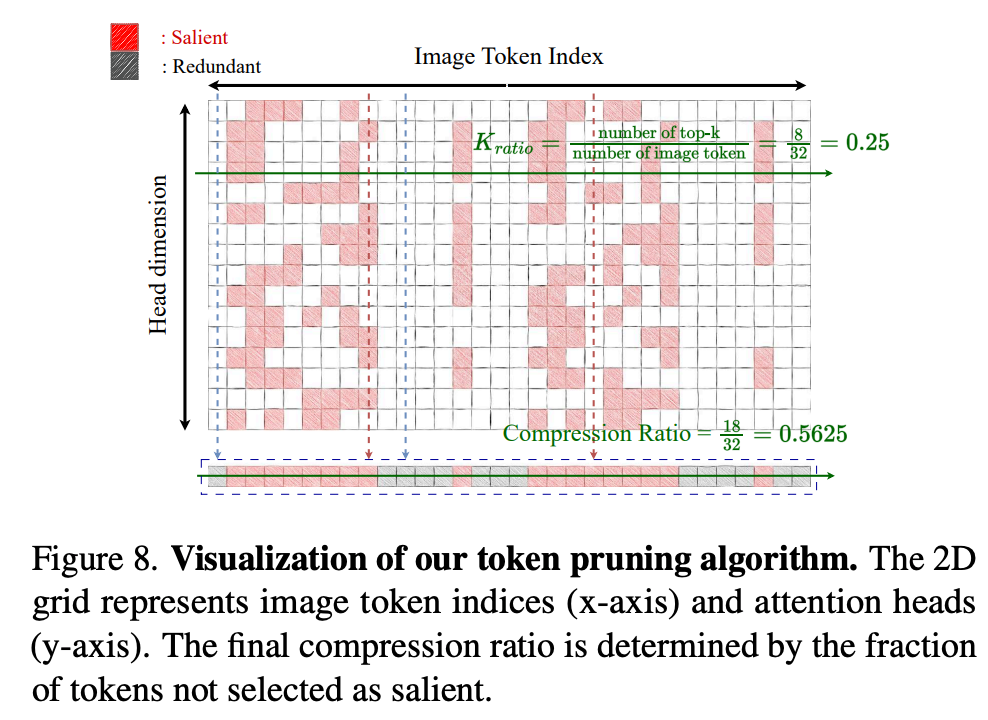
본 방법은 언어 시퀀스로부터 얻은 헤드 단위(headwise) 어텐션 가중치를 활용하여 중요하지 않은 시각 특징을 제거합니다. 첫 번째 크로스 어텐션 레이어에서는 각 헤드가 어텐션 가중치에 기반하여 가장 두드러진 상위-k개의 시각 특징을 선택합니다. 모든 헤드에서 선택된 이들 상위-k 집합의 합집합이 최종 선택된 시각 토큰을 구성하며, 이를 통해 보다 간결 이미지 표현이 가능해집니다.
그림 2. 미학습 언어로 작성된 텍스트가 기계 생성 텍스트인지 아닌지를 분류하는 제안된 모델의 개요. 얼음 심볼은 훈련 중 파라미터가 업데이트되지 않는 모듈을, 불꽃 심볼은 훈련 중 파라미터가 업데이트되는 모듈을 의미함.
실험 결과
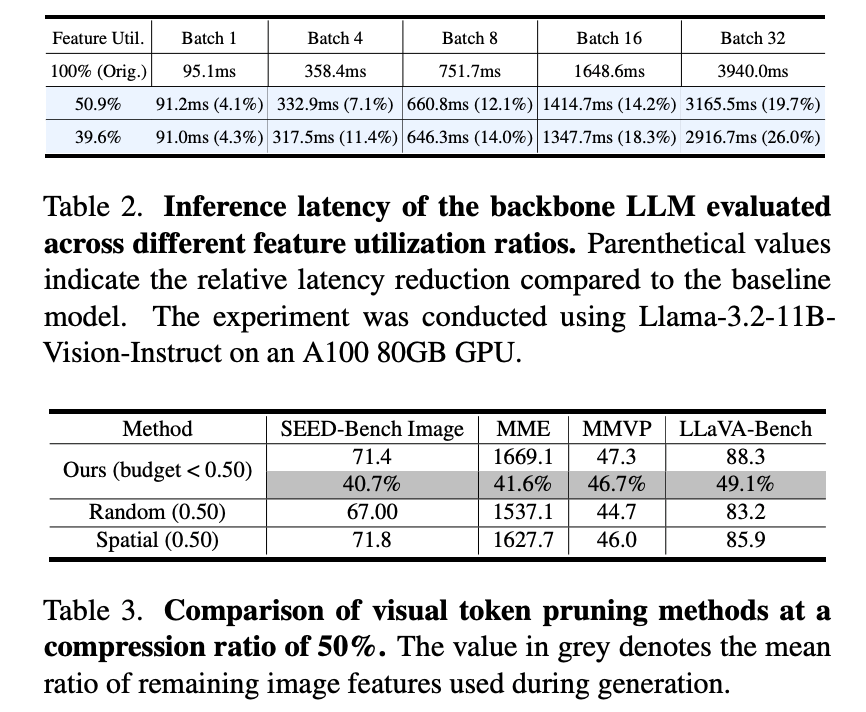
제안된 방법은 크로스 어텐션 레이어에서 key 및 value 입력을 가지치기하여 추론 지연을 줄입니다. 시각 특징은 첫 번째 크로스 어텐션 레이어 이후에 가지치기되므로, key-value projection과 어텐션 연산 모두가 함께 축소됩니다. 또한, 배치(batch) 크기가 커질수록 이러한 최적화의 효과는 더욱 두드러지게 나타납니다.
결론 및 향후 연구 방향
LLaMA-3.2-Vision과 같은 크로스 어텐션 기반 모델은 고품질의 비공개 데이터셋을 활용하여 뛰어난 성능과 효율성을 달성하고 있습니다. 향후 유사한 아키텍처를 기반으로 한 오픈소스 모델들이 등장함에 따라 관련 기술의 발전이 더욱 가속화될 것으로 기대됩니다.
이 연구에 대해 추가로 궁금한 사항이 있으시면 아래 이메일 주소로 언제든지 문의해 주세요: 📧 contact@nota.ai.
또한, AI 최적화 기술에 관심이 있으시면 저희 웹사이트 🔗 netspresso.ai.를 방문해 보세요.