SplitQuant: 엣지 AI 기기에서의 신경망 저비트 양자화를 위한 레이어 분할 기법

Jaewoo Song
Software Engineer, Nota AI
개요
본 연구는 고급 양자화 기법을 지원하지 않는 엣지 AI 기기에서 양자화 정확도를 향상시키기 위한 AI 모델 전처리 방법을 제안합니다.
파라미터에 대한 클러스터링 결과를 기반으로 레이어를 분할함으로써, 단순 선형 양자화 환경에서도 원본 모델과 유사한 수준의 정확도를 달성합니다.
본 연구는 Edge AI Foundation Austin 2025에 채택되었습니다.
논문의 주요 메시지
엣지 AI 기기들은 성능상의 제약으로 인해 고급 양자화 방식을 지원하지 않아 간단한 선형 양자화 방식만 사용할 수 있는 경우가 많습니다. 본 연구는 이러한 제약 속에서도 양자화 정확도를 향상시키기 위해, 파라미터 값에 대한 클러스터링을 기반으로 레이어를 분할하는 AI 모델 전처리 기법(SplitQuant)을 제안합니다. 이 방법을 통해 단순한 양자화 환경에서도 원본 모델에 가까운 성능을 유지할 수 있습니다.
논문의 의의 및 중요성
심층 신경망(Deep Neural Networks, DNNs)에 대한 양자화는 모델의 파라미터 값을 원래의 데이터 타입에서 더 낮은 정밀도의 다른 데이터 타입으로 매핑하여 모델 크기를 줄이고 추론 속도를 높이는 과정입니다. 양자화는 종종 서로 다른 원래 값들을 하나의 양자화된 값에 매핑하게 되는데, 이는 원래 값들의 범위가 양자화 값들의 범위보다 크기 때문입니다. 이로 인해 양자화된 심층 신경망망의 정확도가 저하됩니다. 특히 이상치(outliers)는 양자화 범위를 크게 만들어 정확도를 저하시키는 주요 원인이 됩니다. 기존 방법에서는 이러한 이상치를 제거하는 방법(클리핑)이 종종 사용되었지만, 이 경우 중요한 정보까지 함께 제거되는 문제가 있었습니다.
이 논문은 SplitQuant를 통해 이상치를 유지하면서도 양자화 해상도를 동시에 향상시키는 방법을 제안합니다. SplitQuant는 양자화가 가능한 각 레이어를 수식적으로 동등한 세 개의 레이어로 분할하고, 서로 다른 스케일링 계수를 적용함으로써 원래 값의 범위를 좁히고 이상치의 영향을 완화합니다. 특히, 가중치와 편향은 최적의 분할을 위해 하위, 중간, 상위 클러스터로 나뉘어 클러스터링됩니다. SplitQuant로 심층 신경망를 전처리하면, 양자화 알고리즘이 더 나은 성능을 낼 수 있습니다. SplitQuant를 두 개의 BERT-Tiny 모델에 적용한 결과, INT2 양자화에서 각각 3.3%포인트와 2.1%포인트의 정확도 향상이 나타났으며, 이는 원본 FP32 모델과 유사한 수준의 정확도입니다.
연구 방법론
SplitQuant는 양자화 해상도를 향상시키기 위해 스케일링 계수를 증가시킵니다. 비트 폭이 고정되어 있기 때문에 SplitQuant는 원래 파라미터들의 최대값과 최소값의 차이를 줄여 스케일링 계수를 증가시킵니다.
SplitQuant는 선형 레이어, 합성곱 레이어, 활성화 레이어를 분할한 뒤, 심층 신경망의 기능을 유지하면서 다시 결합합니다. 각 분할된 레이에서는 최대값과 최소값 사이의 범위가 원래 레이어에서보다 좁기 때문에, 양자화 해상도가 향상됩니다.
SplitQuant가 레이어를 어떻게 분할하는지는 아래 그림에 시각적으로 표현되어 있습니다.
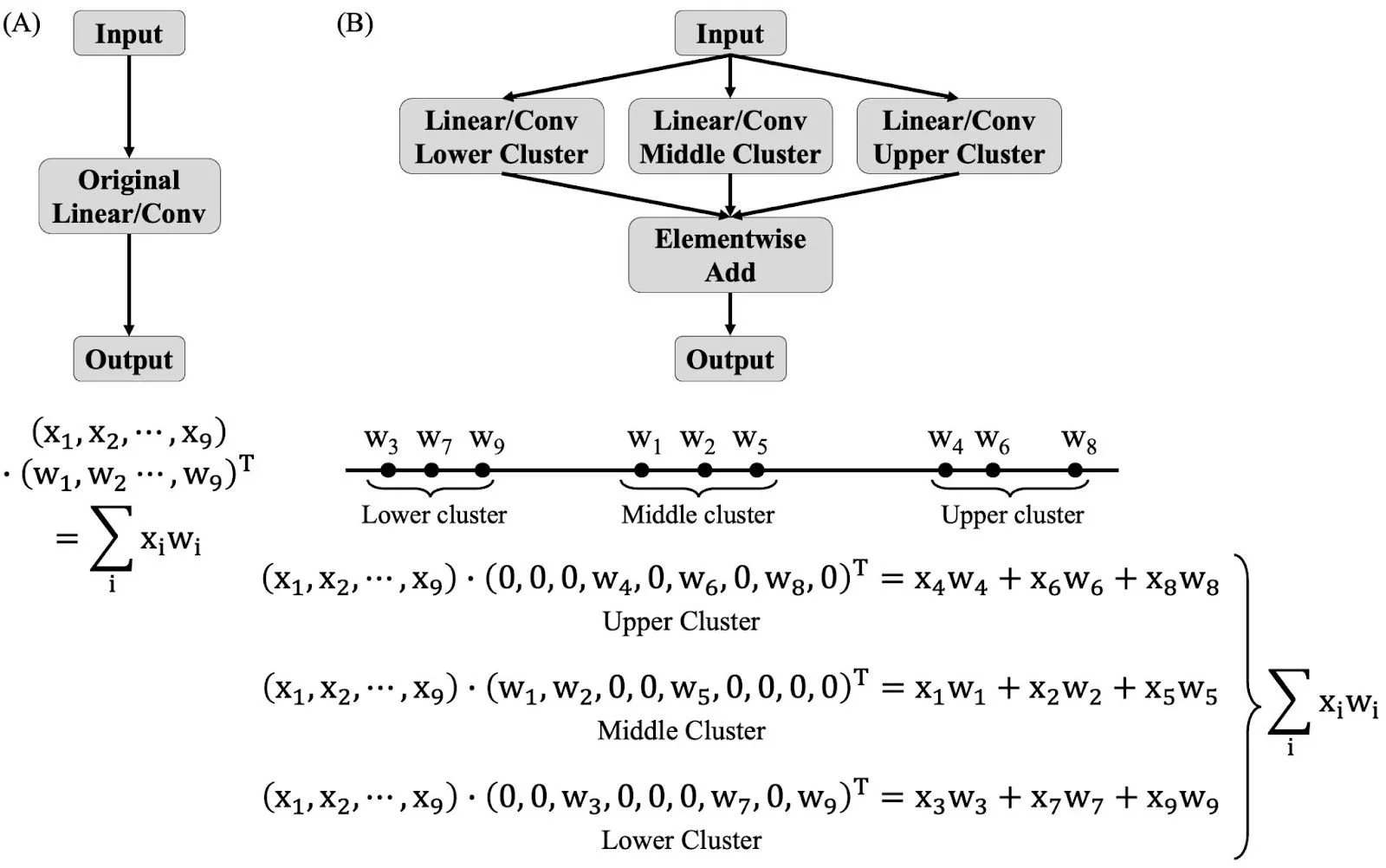
SplitQuant는 가중치와 편향에 대해 k-means 클러스터링을 수행합니다. ‘k = 3’으로 설정하여 가중치와 편향에 대한 파라미터를 하위, 중간, 상위 클러스터로 나눕니다. 초기 클러스터 중심은 greedy k-means++ 알고리즘을 사용해 선택합니다.
이후 각 클러스터링된 파라미터로부터 세 개의 새로운 레이어 생성됩니다. 예를 들어, 하위 레이어 하위 클러스터의 가중치와 편향으로 구성되며, 원본 레이어는 생성된 세 개의 레이어로 대체됩니다. 새로 생성된 각 레이에서 가중치와 편향의 원래 형태를 유지하기 위해, 값이 없는 위치에는 0을 채워 넣습니다.
실험 결과
SplitQuant는 Hugging Face의 BERT-Tiny 모델 두 개에 적용되었으며, 각각 DAIR.AI의 감정 인식 데이터셋과 UC Irvine의 SMS 스팸 탐지 데이터셋에 대해 파인튜닝된 모델입니다. 이 모델들이 선택된 이유는 BERT가 트랜스포머 아키텍처를 효과적으로 대표하며, 모델 크기가 비교적 작아 tinyML 및 엣지 AI에 적합하기 때문입니다.
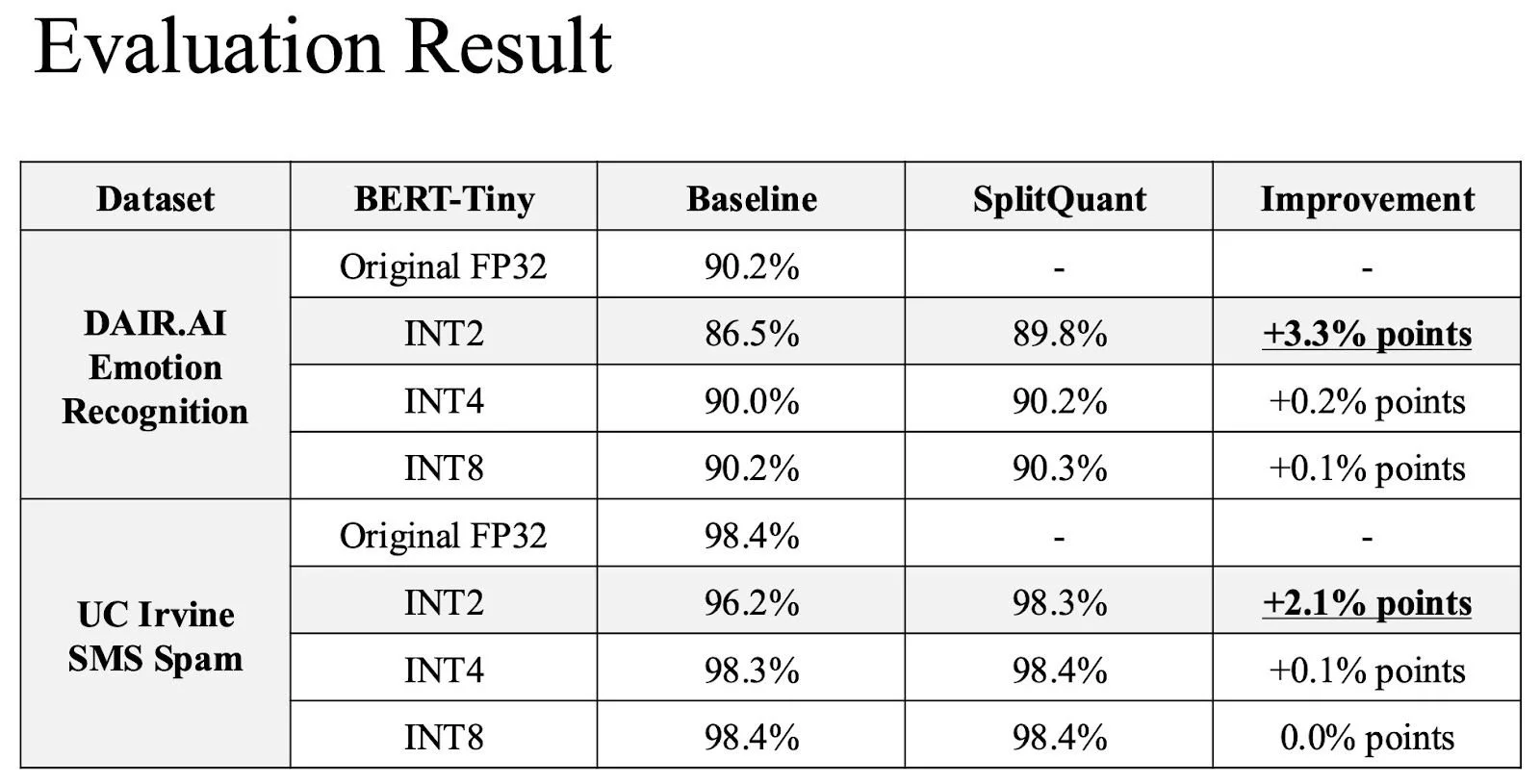
SplitQuant의 효과는 특히 INT2 양자화에서 두드러졌습니다. INT2 양자화의 경우, 감정 인식 정확도가 86.5%에서 89.8%로 3.3%포인트 향상되었고, 스팸 탐지 정확도는 96.2%에서 98.3%로 2.1%포인트 향상되었습니다. 이 향상된 정확도는 각각 90.2%, 98.4%였던 원본 FP32 모델의 정확도에 매우 근접한 수준입니다. 한편, INT4 및 INT8 양자화에서도 성능이 향상되었으나, INT2만큼 극적인 개선은 아니었습니다. 전체 실험 결과는 다음 표에 정리되어 있습니다.
결론 및 향후 연구 방향
SplitQuant는 INT2와 같은 저비트 양자화에서 정확도를 향상시키는 데 매우 효과적인 방법임이 입증되었습니다. 저비트 양자화는 양자화 해상도가 낮아 이상치에 특히 취약한데, SplitQuant는 각 양자화 가능한 레이어를 수식적으로 동등한 세 개의 레이어로 분할함으로써 이상치가 담고 있는 중요한 신호를 유지하면서도 양자화 해상도를 동시에 향상시킵니다.
또한, 가중치와 편향을 최적으로 분할하기 위해 k-means 클러스터링을 활용함으로써 이 과정을 더욱 정교하게 만듭니다. SplitQuant는 다른 양자화 알고리즘과 결합하여 그 성능을 더욱 향상시킬 수 있습니다.
두 개의 파인튜닝된 BERT-Tiny 언어 모델에 대한 실험에서는 INT2 양자화에서 각각 3.3%포인트 및 2.1%포인트의 정확도 향상이 나타났으며, 이는 원본 FP32 모델과 유사한 수준의 정확도입니다. 향후 연구에서는 SplitQuant를 대형 언어 모델에 적용하거나, 희소 신경망 (sparse DNN) 기술의 발전과 결합했을 때의 가능성을 탐색할 수 있을 것입니다.
이 연구에 대해 추가로 궁금한 사항이 있으시면 아래 이메일 주소로 언제든지 문의해 주세요: 📧 contact@nota.ai.
또한, AI 최적화 기술에 관심이 있으시면 저희 웹사이트 🔗 netspresso.ai를 방문해 보세요.