NVIDIA Blackwell; NVFP4가 LLM 추론에 미치는 영향

Seungmin Yang
EdgeFM Lead, Nota AI
개요
NVFP4의 도입으로 NVIDIA의 Blackwell GPU 아키텍처에서 LLM 추론 효율성이 크게 향상됩니다.
Blackwell의 NVFP4 포맷 (RTX PRO 6000) 은 NVIDIA A100과 비교해 LLM 추론 효율성이 최대 2배 향상되며, 정확도 손실이 거의 없어 초저정밀 계산이 실용적이고 신뢰할 수 있음을 입증합니다.
Blackwell 아키텍처에 특화된 경량화/최적화 기술과 멀티모달 확장을 통해 모델을 더 압축하고 최적화 할 수 있는 가능성이 있습니다.
소개
2024년 3월, NVIDIA는 Blackwell—차세대 GPU 아키텍처를 발표했습니다. 이 아키텍처는 5세대 Tensor Cores의 주요한 성능 향상을 가져왔으며, 이제 FP4 (및 FP6)를 기본적으로 지원하여 초저정밀 AI 연산을 가능하게 합니다. 이 글에서는 Blackwell을 위한 NVIDIA의 FP4 데이터 형식인 NVFP4에 중점을 두고 있습니다. Blackwell은 또한 "Tensor Memory"라는 새로운 온칩 메모리 계층을 도입하여 GEMM 커널을 변경했지만, 해당 내용은 이 글에서 다루지 않습니다.
NVFP4가 중요한 이유는 무엇인가요?
기존의 FP4 방식은 각 값을 4비트로 압축하는 방식으로, 대역폭과 연산 성능에는 유리하지만 정확도의 손실을 초래할 수 있습니다. NVFP4는 이 정확도와 성능 사이의 균형을 마이크로 블록 스케일링 기법으로 해결합니다. 이 기법에서는 값을 16개의 블록으로 묶어 각 블록에 고정밀 FP8 (E4M3) 스케일링 팩터를 공유하며, 추가로 각 텐서에 FP32 스케일을 적용합니다. 실제로, 각 4비트 숫자는 아주 작은 인덱스이며, 스케일은 계산 중에 크기를 복원하는 "확대 수준" 역할을 합니다.
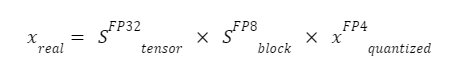
여기서:
xFP4quantized: E2M1 형식의 4비트 양자화된 값(1개의 부호 비트, 2개의 지수 비트, 1개의 가수 비트)으로, 매우 압축적이지만 정밀도가 낮습니다.
SFP8block: FP8 (E4M3) 형식의 블록 단위 스케일이 16개의 연속된 FP4 값에 걸쳐 공유되며, 이를 통해 상대적인 크기를 복원하는 로컬 줌 팩터가 제공됩니다.
SFP32tensor: 모든 블록 스케일이 안정적인 범위 내에 있도록 텐서마다 한 번 적용되는 FP32 스케일입니다.
이 두 단계의 스케일링 방식은 동적 범위를 유지하고 양자화 오류를 줄이면서, 데이터를 매우 작은 크기로 유지합니다. 이는 대형 Transformer 기반의 LLM 추론에 특히 효과적인 기술입니다.
이 글에서 다루는 내용은 무엇인가요?
NVFP4의 하드웨어 경로와 NVFP4의 레이아웃을 기반으로, Blackwell 워크스테이션 GPU인 RTX PRO 6000에서 LLM 추론을 측정하고, NVFP4가 가장 효과적인 부분과 주의가 필요한 부분에 대해 설명합니다. RTX PRO 6000은 Blackwell 클래스의 프로 GPU로, 5세대 Tensor Cores와 96GB GDDR7을 탑재하고 있어 On-Premise LLM 서비스에 실용적인 타깃이 됩니다.
실험 설정
프레임워크 & 데이터

타깃 장치

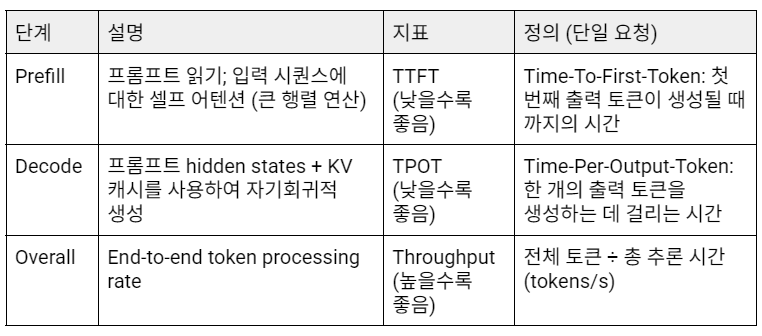
효율성 지표
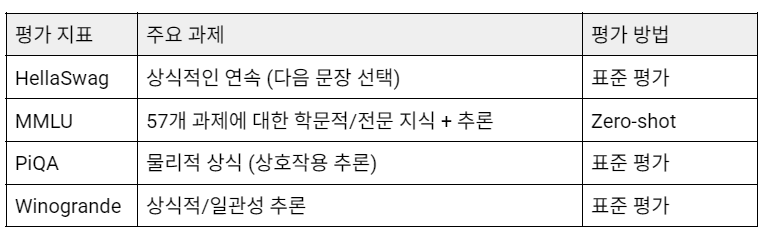
정확도 평가 지표
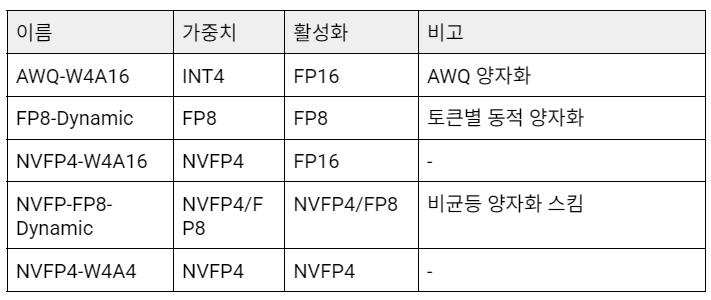
양자화 변형
실험 결과
효율성
Y축의 척도가 패널마다 다르므로(예: 3.0초 vs 2.0초), 장치 간 절대 비교는 피해야 합니다. 여기서 초점은 각 GPU 내에서 상대적인 성능입니다.
TTFT (Prefill 단계)
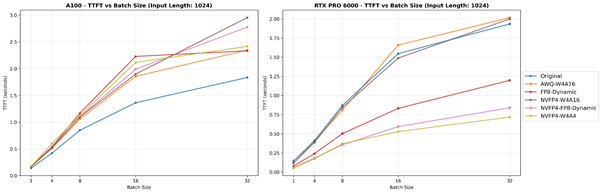
입력 토큰 길이(1024)가 고정된 TTFT-배치 크기 그래프입니다. 왼쪽 그림은 A100에서의 결과를, 오른쪽 그림은 RTX PRO 6000에서의 결과를 나타냅니다.

배치 크기(16)가 고정된 TTFT-입력 토큰 길이 그래프입니다. 왼쪽 그림은 A100에서의 결과를, 오른쪽 그림은 RTX PRO 6000에서의 결과를 나타냅니다.
A100 (Ampere)에서는 Original (BF16) 모델이 모든 조건에서 가장 낮은 TTFT 값을 기록합니다. 이는 A100의 Tensor Core가 FP16/BF16을 최적의 처리 경로(~312 TFLOPS 밀집 처리, 624 TFLOPS 희소 처리[2])로 기본적으로 지원하기 때문입니다. 반면, FP8 및 FP4 연산은 Ampere에서 기본적으로 지원되지 않으며, 더 높은 정밀도의 커널을 통해 모방됩니다. 이로 인해 BF16과 비교했을 때 지연 시간이 절감되지 않습니다.
RTX PRO 6000 (Blackwell)에서는 NVFP4-W4A4가 일관되게 가장 빠른 TTFT를 기록하며, 그 뒤를 NVFP4-FP8-Dynamic이 잇습니다. Blackwell의 5세대 Tensor Core는 FP4/FP6/FP8을 기본적으로 지원하여 NVFP4 작업이 낮은 정밀도 연산과 대역폭 효율성을 완전히 활용할 수 있습니다. 배치 크기나 입력 시퀀스 길이가 증가하면 행렬 곱셈 부하와 메모리 압력이 증가하면서 네이티브 FP4 실행의 장점이 더욱 두드러지게 나타납니다. 이는 Blackwell이 이전 아키텍처들과 비교해 Prefill 단계에서 뛰어난 효율성을 보여준다는 것을 시사합니다.
그러나 소프트웨어와 커널의 성숙도(예: vLLM 런타임 및 NVFP4/FP8 커널 구현 등)가 여기서 보여진 절대적인 차이에 영향을 미칠 수 있음을 유의해야 합니다. 시간이 지나면서 프레임워크와 커널이 발전함에 따라 절대적인 TTFT 값과 상대적인 차이가 달라질 수 있으므로, 이 결과는 vLLM v0.10.1.1을 기준으로 한 상대적인 추세임을 기억하셔야 합니다.
TPOT (Decode 단계)

입력 토큰 길이(1024)가 고정된 TPOT-배치 크기 그래프입니다. 왼쪽 그림은 A100에서의 결과를, 오른쪽 그림은 RTX PRO 6000에서의 결과를 나타냅니다.
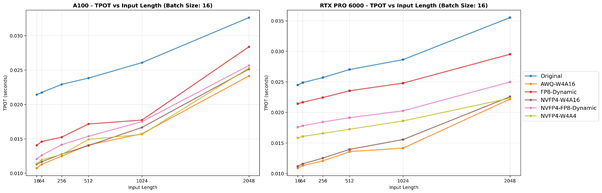
배치 크기(16)가 고정된 처리량-입력 토큰 길이 그래프입니다. 왼쪽 그림은 A100에서의 결과를, 오른쪽 그림은 RTX PRO 6000에서의 결과를 나타냅니다.
두 GPU의 일관된 경향: 수치 정밀도가 낮을수록 TPOT(출력 토큰당 시간)가 작아집니다. 이는 Decode 단계의 본질적인 특성으로, Key-Value(KV) 캐시의 도입이 토큰당 행렬 곱셈 계산의 부하를 줄이고, 주요 병목 현상이 계산에서 메모리 접근으로 이동하기 때문입니다. 그 결과, 데이터를 최소화하여 이동시키는 형식은 메모리 대역폭을 효율적으로 활용할 수 있어 토큰당 지연 시간이 줄어듭니다.
두 장치를 비교할 때, A100 (Ampere)는 대부분의 조건에서 RTX PRO 6000 (Blackwell)보다 낮은 TPOT를 나타냅니다. 이는 주로 A100의 높은 메모리 대역폭(≈2,039 GB/s, HBM2e)이 RTX PRO의 GDDR7 대역폭(≈1,792 GB/s)보다 높아 메모리 바운드 시나리오에서 명확한 이점을 제공하기 때문입니다. 그러나 입력 길이나 배치 크기가 증가함에 따라, 작업 부하는 메모리 바운드에서 컴퓨트 바운드로 전환됩니다. 이 시점에서 Blackwell의 네이티브 FP4/FP8 Tensor Core 경로가 강점을 발휘하기 시작하여, NVFP4 기반 모델이 높은 정밀도의 모델을 초과하는 교차점을 만들어냅니다. 이는 Prefill 단계에서 나타난 경향과 유사합니다.
흥미로운 점은 RTX PRO 6000에서 AWQ-W4A16뿐만 아니라 NVFP4-W4A16도 완전한 저비트 NVFP4 변형인 NVFP4-FP8-Dynamic 및 NVFP4-W4A4보다 더 낮은 TPOT를 달성한다는 점입니다. AWQ의 경우, 이는 소형/중형 배치 디코드 작업에 유리한 특수한 AWQ-Marlin 커널을 사용하기 때문에 쉽게 설명할 수 있습니다. 이는 커널 구동 오버헤드를 줄이고, 스케줄링 및 메모리 재사용을 개선합니다. 그러나 NVFP4-W4A16의 경우, NVFP4 를 위한 Marlin 커널이 없기에 다르게 설명됩니다. 이 모델은 FP4로 가중치만 압축하고 FP16 활성화를 유지하는데, 이를 통해 FP16 축적 경로에서 잘 최적화된 GEMM 커널을 사용하여 효율적으로 동작하게 됩니다.
반면, FP4/FP8 커널은 Blackwell에서 기본적으로 지원되지만 vLLM과 CUTLASS에서 최적화가 초기 단계에 있기 때문에 블록 단위 활용 및 역양자화(de-quantization) 단계에서 비효율적인 오버헤드가 발생할 수 있습니다. 또한, 디코딩은 반복적인 가중치 행렬 곱셈보다는 KV 캐시 읽기에 주로 영향을 받기 때문에, 완전히 양자화된 활성화(Activation)의 이점이 제한적이며, 추가적인 역양자화 연산이 이론적인 성능 향상을 상쇄할 수도 있습니다. 따라서 NVFP4-W4A16은 현재 소프트웨어 조건 하에서 실질적인 지연 시간이 완전한 저비트 NVFP4 구성보다 빠를 수 있습니다.
처리량(Overall 단계)
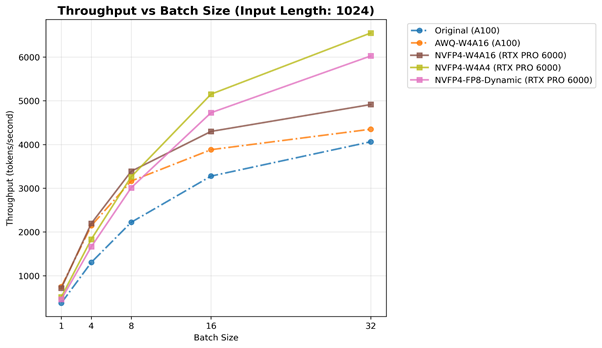
입력 토큰 길이(1024)가 고정된 처리량-배치 크기 그래프입니다. 실선은 RTX PRO 6000 에서의 최적 설정, 점선은 A100 에서의 최적 설정을 의미합니다.
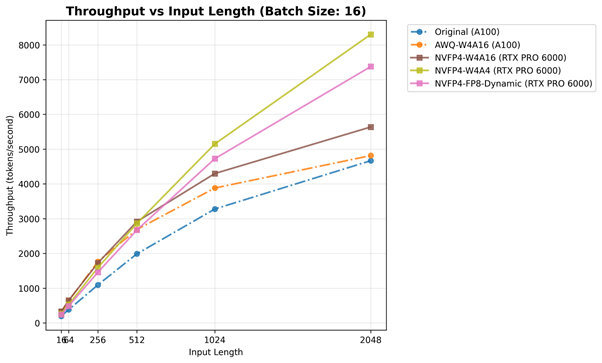
배치 크기(16)가 고정된 처리량-입력 토큰 길이 그래프입니다. 실선은 RTX PRO 6000 에서의 최적 설정, 점선은 A100 에서의 최적 설정을 의미합니다.
Prefill (TTFT) 및 Decode (TPOT) 단계의 결과를 바탕으로, 처리량은 두 동작을 모두 통합하는 요약 지표로 볼 수 있습니다. TTFT는 입력 프롬프트를 읽고 처리하는 지연 시간을 반영하고, TPOT는 토큰당 생성 효율성을 나타냅니다. 반면, 처리량은 전체 추론 파이프라인의 전반적인 성능을 나타냅니다. 작은 배치 크기에서는 커널 실행 및 메모리 지연 시간이 지배적이지만, 작업 부하가 증가함에 따라 이러한 효과는 줄어들고, 하드웨어는 실제 처리량 한계에 가깝게 작동합니다.
A100 (Ampere)에서는 Original (BF16) 및 AWQ-W4A16 설정 모두 무난한 성능 확장을 보이며, 약 4,000–5,000 토큰/초까지 도달합니다. 앞서 TTFT/TPOT 분석에서 논의된 바와 같이, 이는 Ampere에서 FP4/FP8 실행이 기본적으로 지원되지 않기 때문에 GPU가 초저정밀도 계산의 이점을 완전히 활용할 수 없고, FP16/BF16 경로가 가장 최적화된 상태를 유지하기 때문입니다.
반면, RTX PRO 6000 (Blackwell)은 명확한 우위를 보여줍니다. 모든 NVFP4 기반 모델이 A100 에서의 최적 설정보다 전반적으로 뛰어난 성능을 보이며, NVFP4-W4A4 및 NVFP4-FP8-Dynamic은 6,000–8,000 토큰/초까지 도달하여, A100보다 약 1.7배에서 2배 더 높은 처리량을 보여줍니다. 이 결과는 앞서 분석한 Prefill 단계의 이점과 Decode 단계에서의 메모리 효율성이 결합되어 큰 전체 성능 향상을 만들어내는 것을 의미합니다. 즉, Blackwell의 5세대 Tensor Core는 FP4/FP8 연산을 기본적으로 가속화하여 산술 밀도 (Arithmetic Density) 를 크게 증가시킵니다.
NVFP4 계열 모델들을 비교했을 때, 배치 크기나 입력 길이가 커짐에 따라 NVFP4-FP8-Dynamic이 NVFP4-W4A16보다 좋은 성능을 보입니다. 이는 Activation 양자화를 가중치와 같은 FP8로 수행하여 대규모 컴퓨트 바운드 작업에서 스케일링의 영향을 크게 줄였기 때문입니다. 그러나 작은 배치에서는 동적 스케일링 비용이 이러한 이점을 상쇄할 수 있어, NVFP4-W4A16이 약간 더 효율적일 수 있습니다.
이 실험을 통해, Blackwell이 작업 부하 크기에 커짐에 따라 성능을 지속적으로 확장하며, 이는 초저정밀도 NVFP4 형식에서 더 큰 확장성을 보임을 확인할 수 있었습니다. 이 결과들은 Blackwell 아키텍처와 NVFP4 양자화의 조합이 전체 추론 파이프라인에서 안정적인 효율성을 이끌어내어 차세대 LLM 작업에 결정적인 이점을 제공한다는 것을 보여줍니다.
정확도
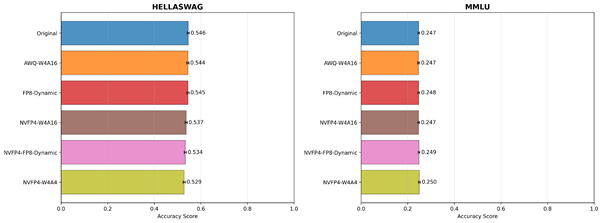
각 모델 변형에 대한 학술 평가 지표 점수의 막대 그래프입니다.
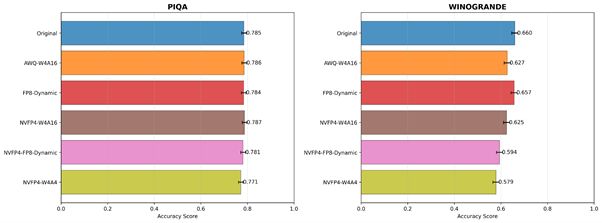
각 모델 변형에 대한 학술 평가 지표 점수의 막대 그래프입니다.
학술 평가 지표 결과는 지연 시간과 처리량 분석을 보완하여 양자화가 모델 품질에 미치는 영향을 보여줍니다. HellaSwag, MMLU, PiQA 전반에서 모든 정밀도 형식 간의 정확도 차이는 ±0.005–0.01 범위 내로 통계적으로나 실용적으로 무시할 수 있는 수준입니다. 이러한 작은 차이는 무작위 시드 (random seed), 프롬프트 순서, 또는 토큰화 세부 사항과 같은 비결정적인 요인으로 쉽게 발생할 수 있습니다.
가장 실용적으로 사용되는 관련 선행 논문과 수치를 비교해보면, Lin et al.[3]은 4비트 AWQ 양자화의 0.1-0.7의 정확도 하락에 대해 사실상 ‘손실 없는’ 성능을 유지한다고 보여주었고, Xiao et al.[4]은 4비트/8비트 양자화 후 정확도 차이가 <0.3%라고 보고했습니다. 이를 통해 Blackwell의 NVFP4 형식이 FP16/BF16 기준에 비해 최대 2배 높은 효율성을 달성하면서도 정확도를 거의 손실 없이 유지한다고 볼 수 있습니다.
단, Winogrande는 다소 더 큰 차이를 보이는데, 이는 언어적 추론 복잡성 때문일 가능성이 큽니다. Winogrande는 의미론적으로 가장 민감한 평가 지표 중 하나인 상식적 대명사 해결을 평가하며, 작은 정밀도의 차이가 문맥 이해에 직접적으로 영향을 미칠 수 있습니다. 또한 상대적으로 작은 데이터셋 크기와 문장의 다양성으로 인해 정확도의 변동성이 더 크고, 이로 인해 미세한 수치적 변동이 나타날 수 있습니다. 따라서 이러한 편차는 모델 성능 저하가 아니라 작업 수준의 민감도로 해석해야 합니다.
물론, 이 평가 지표들은 실제 LLM 배포 시나리오를 완전히 대표하는 것은 아닙니다. HellaSwag, MMLU, PiQA, Winogrande는 일반적인 추론 및 상식적인 작업을 다루고 있지만, 대규모 지식 검색, 다중 턴 대화, 코딩, 수학적 추론 등은 포함하지 않습니다. 그럼에도 불구하고 NVFP4가 매우 낮은 비트(FP4) 설정에서도 거의 손실 없는 정확도를 유지하는 것은 주목할 만하며, 이는 추가 최적화를 위한 강력한 잠재력을 시사합니다. 예를 들어, 더 나은 스케일링 전략, Calibration set 구성 또는 구조 인식 양자화를 통해 NVFP4 기반 압축이 실제로 사실상 손실 없는 형태로 구현될 수 있는 가능성을 보여줍니다.
결론
이번 실험은 Blackwell 아키텍처와 NVFP4 데이터 형식이 LLM 추론 효율성을 획기적으로 향상할 수 있음을 입증했습니다. Prefill 단계에서의 네이티브 FP4 연산과 Decode 단계에서의 향상된 메모리 효율성 덕분에 A100 (Ampere)보다 최대 2배 높은 처리량을 기록하면서도 정확도 저하는 통계적으로 미미한 수준에 그쳤습니다. 이러한 결과는 NVFP4가 FP16/BF16 수준의 품질을 유지하면서 초저정밀 연산의 실질적인 이점을 제공한다는 것을 보여줍니다. 이는 낮은 정밀도의 산술 연산이 단순한 최적화 기법이 아니라 대규모 언어 모델 추론을 위한 실행 가능한 가속 기술임을 의미하며, 향후 효율성과 비용 효과성을 개선하는 명확한 방향을 제시합니다.
노타는 이미 비전-언어 모델(VLM) 기반 솔루션을 적극적으로 개발하고 있으며, 이 연구의 결과를 기반으로 NVFP4 추론을 멀티모달 작업 부하에 최적화하는 작업을 진행할 예정입니다. 시각적 특성은 일반적으로 텍스트 데이터의 특성보다 더 연속적이고 밀집되어 있기 때문에, 보다 세밀한 최적화가 필요합니다.
(1) 멀티모달 아키텍처에 특화된 양자화 기법 연구
(2) NVFP4 최적화된 GEMM/GEMV 계산 커널 및 스케줄링 방법 개발
(3) 본 연구에서 다루지 않은 텐서 메모리 계층에 대한 분석 및 특화된 최적화 연구
이와 같은 향후 연구를 통해, 노타는 차세대 대규모 모델의 실시간 고효율 추론을 선도할 것입니다.
레퍼런스
[1]https://www.nvidia.com/content/dam/en-zz/Solutions/design-visualization/quadro-product-literature/workstation-datasheet-blackwell-rtx-pro6000-x-nvidia-us-3519208-web.pdf
[2]https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/a100/pdf/nvidia-a100-datasheet-us-nvidia-1758950-r4-web.pdf
[3]Lin, Ji, et al. "Awq: Activation-aware weight quantization for on-device llm compression and acceleration." Proceedings of machine learning and systems 6 (2024): 87-100.
[4]Xiao, Guangxuan, et al. "Smoothquant: Accurate and efficient post-training quantization for large language models." International conference on machine learning. PMLR, 2023.
이 연구에 대해 추가로 궁금한 사항이 있으시면 아래 이메일 주소로 언제든지 문의해 주세요: 📧 contact@nota.ai.
또한, AI 최적화 기술에 관심이 있으시면 저희 웹사이트 🔗 netspresso.ai.를 방문해 보세요.