Powered by
Nota Vision Agent (NVA)
현장을 가장 잘 아는 생성형 AI 기반 영상 관제 솔루션이 작업자 안전을 지키고 사고로 인한 손실을 최소화합니다.
산업 안전 솔루션

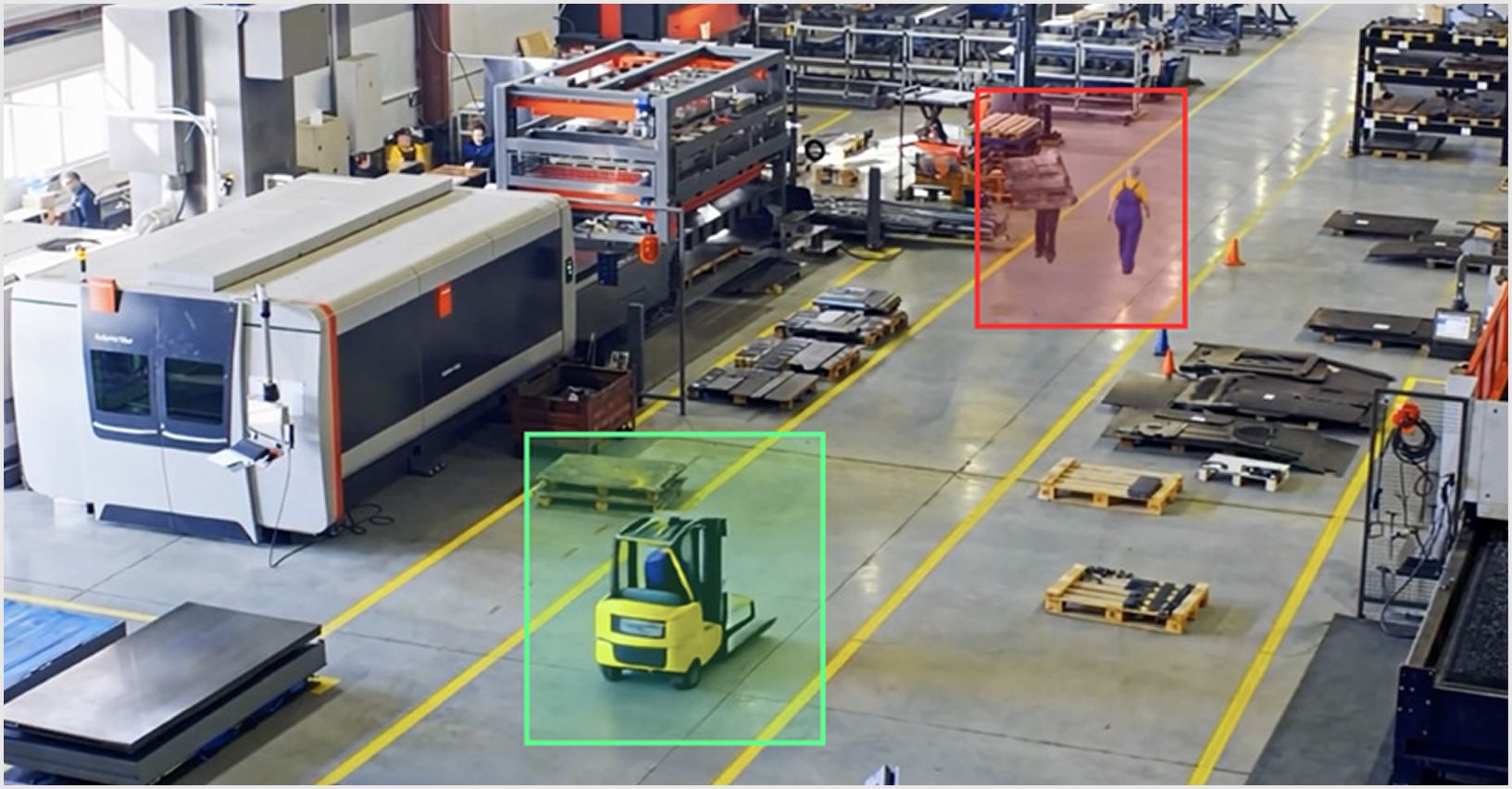
학습 필요 없이 예외적인 위험 상황까지 감지
비전언어모델(VLM)을 활용하여 기존 컴퓨터비전모델(CV)로는 감지하기 어려운
복잡한 이벤트를 자율적으로 인지하고 표준작업절차(SOP) 기반 대응 지원

빠른 도입과 유연한 확장성
복잡한 설치나 학습 필요 없이 2~3주 내 즉시 적용 가능하며,
운영 환경에 따른 유연한 채널 확장 지원

상황 맥락 기반의 인사이트
자동 분석 리포트 생성,
자연어 기반 영상 검색 및 질의응답 기능 제공
학습 필요 없이 예외적인 위험 상황까지 감지
비전언어모델(VLM)을 활용하여 기존 컴퓨터비전모델(CV)로는 감지하기 어려운
복잡한 이벤트를 자율적으로 인지하고 표준작업절차(SOP) 기반 대응 지원
산업 현장의 모든 위험 상황을 예방하는
50+ 안전 관리 항목